
TxAgent: an AI Agent for Therapeutic Reasoning Across a Universe of 211 Tools
March 24, 2025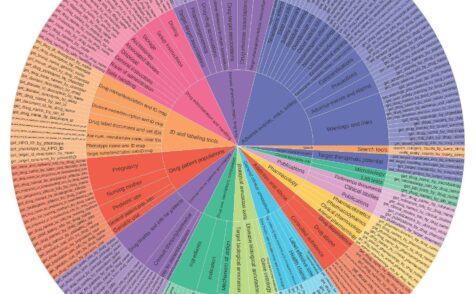
Making safe and effective drug decisions requires analyzing complex interactions, patient-specific factors, and up-to-date biomedical knowledge. Most AI models fail at this task, relying on outdated training data and struggling with real-time decision-making.
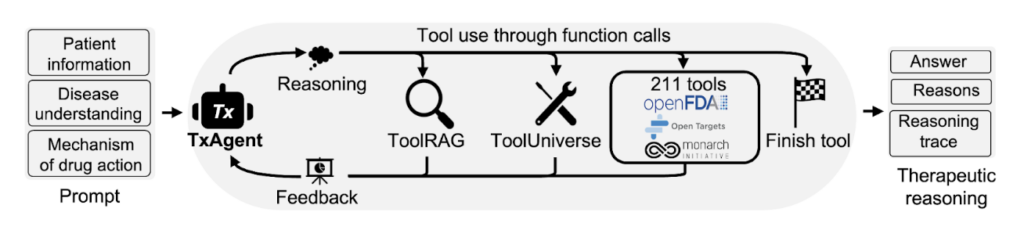
TxAgent changes that. It is an AI agent built for therapeutic reasoning capable of multi-step reasoning, real-time knowledge retrieval, and tool-assisted decision-making (Figure 1). TxAgent does not just generate text. It reasons through therapeutic decisions, step by step. By analyzing drugs at molecular, pharmacokinetic, and clinical levels, it can reason about drug interactions and contraindications and perform personalized treatment selection. Unlike AI models, which rely on static training data, TxAgent retrieves the latest biomedical insights and explains every decision with transparent reasoning traces.
ToolUniverse is what makes TxAgent truly unique. It consolidates 211 expert-curated tools, covering everything from all FDA-approved drugs since 1939 to disease annotations. Unlike AI models that rely on static knowledge, TxAgent actively retrieves the latest biomedical data to ensure its decisions are based on real-time, verifiable sources like OpenFDA, Open Targets, and the Human Phenotype Ontology. TxAgent introduces ToolRAG, an ML retrieval model that selects the most relevant tools from ToolUniverse based on reasoning tasks. TxAgent is an open model.
How it works: Multi-step reasoning meets real-time knowledge retrieval
TxAgent is designed to go beyond simple predictions. It analyzes, verifies, and iterates through therapeutic decisions in a structured way (Figure 2). Here’s how:
- Retrieves trusted knowledge in real-time: Unlike AI models trained on static data, TxAgent calls external biomedical tools to pull real-time information about drug interactions, mechanisms, and contraindications.
- Performs multi-step reasoning: It doesn’t just predict answers. It builds structured reasoning chains, ensuring that every step of its logic is transparent and backed by evidence.
- Selects the right tools for the task: TxAgent integrates with ToolUniverse, a curated set of 211 specialized biomedical tools, including FDA-approved drugs, Open Targets, and disease annotations. Based on the problem at hand, it chooses the right tools dynamically.
- Executes function calls for precision: Instead of generating text alone, TxAgent executes structured function calls to analyze therapeutic reasoning tasks that require clinical validation.
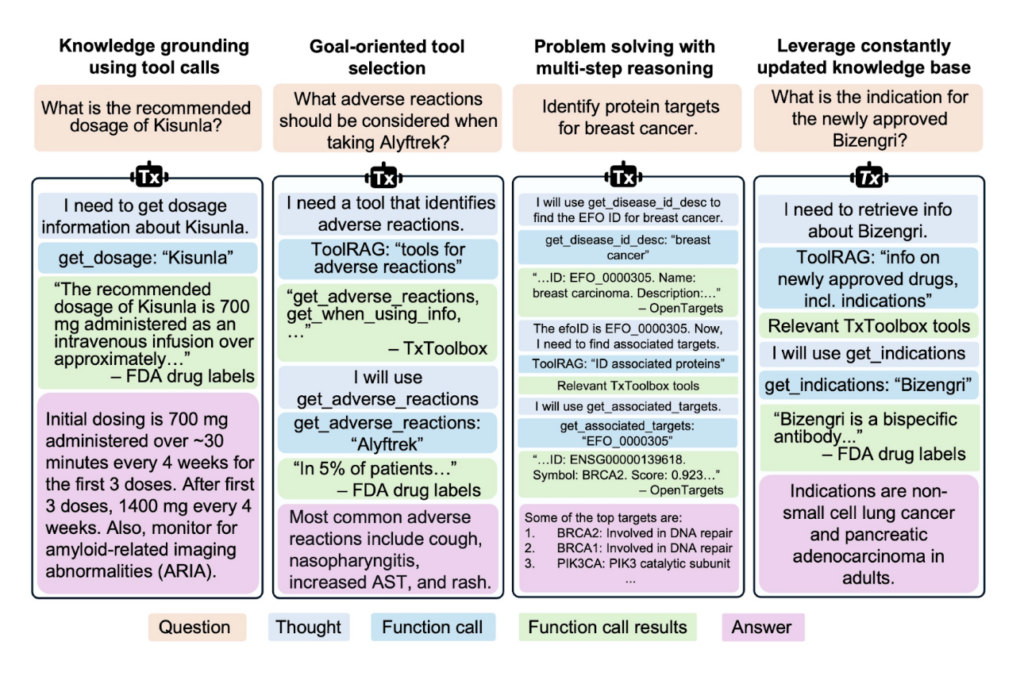
TxAgent runs on ToolRAG, an ML-based retrieval model that intelligently selects the most relevant tools from ToolUniverse. Its decisions are both explainable and adaptable to new knowledge.
ToolUniverse: TxAgent uses tools for real-time knowledge retrieval
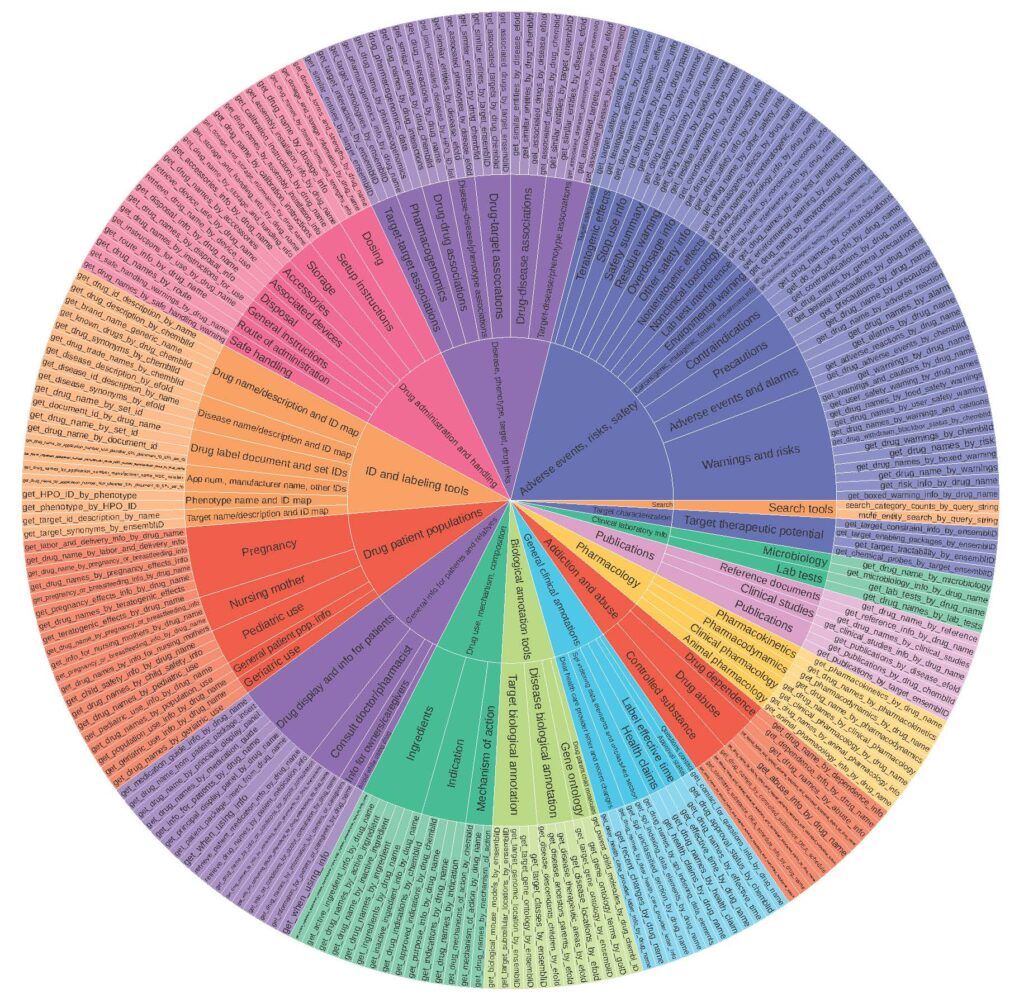
TxAgent is powered by ToolUniverse, a curated set of 211 biomedical tools that provide up-to-date, verifiable drug information. These tools pull from authoritative sources like OpenFDA, Open Targets, and the Human Phenotype Ontology, ensuring TxAgent can access the most current data on drug mechanisms, interactions, and safety profiles (Figure 3).
Unlike AI models that rely on outdated, static training data, ToolUniverse operates in real-time. It continuously integrates new drug approvals, updated clinical guidelines, and emerging safety alerts, making sure TxAgent is always working with the latest scientific insights. This allows TxAgent to retrieve specific, evidence-backed knowledge rather than relying on approximations or outdated references.
At its core, ToolUniverse is more than just a database. It is a knowledge engine that selects and retrieves the most relevant tools for a given reasoning task. Whether identifying drug-drug interactions, analyzing pharmacokinetics, or verifying regulatory status, TxAgent leverages ToolUniverse to provide clear, explainable decision pathways.
Training TxAgent: Learning to reason, not just memorize
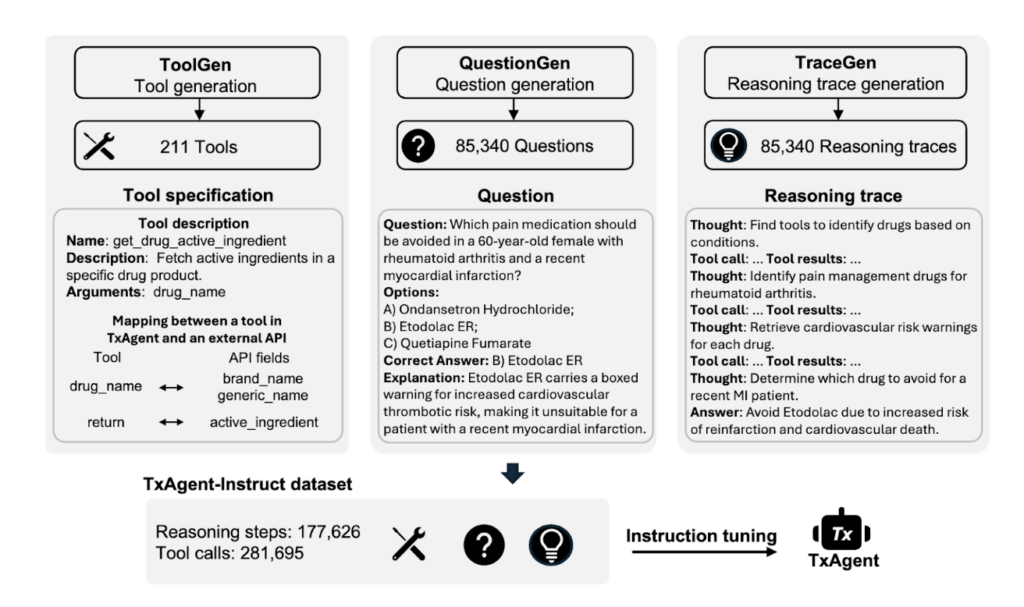
TxAgent is trained using TxAgent-Instruct, a massive dataset for multi-step reasoning and tool-based decision-making. Unlike models that passively absorb knowledge, TxAgent retrieves, evaluates, and synthesizes information on demand.
At the core of TxAgent-Instruct is a multi-agent system that generates training data across three categories (Figure 4):
- Tooling dataset – Augmented descriptions of 211 tools from ToolUniverse, ensuring TxAgent learns how to select and use tools dynamically rather than memorizing fixed responses.
- Therapeutic question dataset – A collection of 85,340 structured questions created by the QuestionGen agent, covering complex reasoning tasks such as drug interactions, safety assessments, and pharmacology.
- Reasoning trace dataset – Built by TraceGen, this dataset contains 177,626 structured reasoning steps and 281,695 function calls, modeling how an AI agent should process biomedical queries step by step.
TxAgent is fine-tuned on this dataset using Llama-3.1-8B-Instruct, an open-source large language model. Training on 378,027 instruction-tuning samples, TxAgent does not just predict answers. It learns to reason through them. This allows it to execute structured function calls instead of relying solely on text-based predictions, adapt to new knowledge in real-time to ensure decisions are always based on the latest biomedical data, and provide transparent reasoning traces, allowing users to see exactly how each decision is made.
TxAgent achieves high accuracy in drug reasoning and tool-based retrieval
TxAgent outperforms larger language and tool-augmented models across five newly introduced benchmarks: DrugPC, BrandPC, GenericPC, DescriptionPC, and TreatmentPC. These benchmarks evaluate drug selection, reasoning accuracy, and the model’s ability to process structured and unstructured queries.
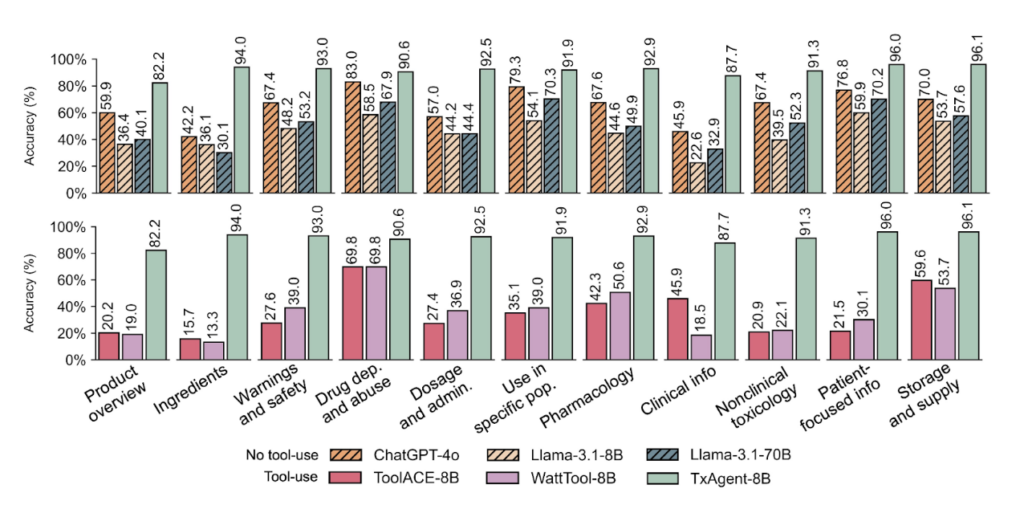
On DrugPC, which tests 11 core drug reasoning tasks, TxAgent achieves 92.1% accuracy in the open-ended setting, where it answers without predefined choices (Figure 5). This result surpasses GPT-4o by 25.8% (GPT-4o: 66.3%) and Llama-3.1-70B-Instruct by 39.3% (Llama-3.1-70B-Instruct: 52.8%). TxAgent, based on the fine-tuned 8-billion parameter Llama-3.1-8B-Instruct model, outperforms much larger models while maintaining computational efficiency.
TxAgent also performs better than specialized tool-augmented models, including ToolACE and WattTool. Unlike these models, which struggle with multi-step reasoning and tool selection, TxAgent retrieves and applies relevant tools from its 211 biomedical tools. This approach improves the accuracy and relevance of its responses.
TxAgent handles different ways of referencing drug names more consistently than other models. While most models perform inconsistently when drugs appear as brand names, generic names, or descriptions, TxAgent maintains a low accuracy variance of less than 0.01. Why is this important? Because other models like GPT-4o show a massive 9.96 variance, meaning they struggle when drugs are referenced differently. On DescriptionPC, which tests the model’s ability to identify drugs based on descriptive text, TxAgent achieves 56.5% accuracy, 8.3% higher than GPT-4o.
TxAgent also ranks highest in personalized treatment selection. On TreatmentPC, a benchmark that evaluates 456 treatment scenarios, TxAgent scores 13.6% higher than GPT-4o and 25.4% higher than Llama-3.1-70B-Instruct in the open-ended setting. These results show that TxAgent improves accuracy in complex reasoning tasks and adapts effectively to new biomedical knowledge.
How does TxAgent compare to the best AI models today? It outperforms DeepSeek-R1, a 671B parameter model, by 7.5% in open-ended therapeutic tasks. These benchmarks highlight a critical AI limitation: most models struggle with real-world drug decision-making because they lack structured, tool-assisted reasoning. TxAgent solves this by integrating real-time biomedical knowledge and dynamically selecting the right tools for each task, suggesting that reasoning combined with tool-based retrieval can improve accuracy more than increasing model size. DeepSeek-R1 relies on internal knowledge, which can lead to hallucinations and misjudgments (Figure 6). TxAgent, in contrast, retrieves information from trusted sources such as FDA drug labels, which reduces errors and improves output reliability.

Conclusion
TxAgent integrates real-time knowledge retrieval, structured multi-step reasoning, and dynamic tool selection for biomedical reasoning. Unlike static models, it retrieves the latest information from trusted sources, applies structured reasoning, and selects relevant tools. TxAgent’s code and models are open-source:
TxAgent is not just another AI model. It is a new way of thinking about AI-powered therapeutic reasoning. By combining real-time knowledge retrieval, structured multi-step reasoning, and dynamic tool selection, it sets a new standard for biomedical AI. Open-source and built for transparency, TxAgent paves the way for AI systems that do not just predict: they reason, adapt, and evolve.