
This blog is adapted from
Transcendence: Generative Models Can Outperform the Experts That Train Them
Transcendence: Generative Models Can Outperform the Experts That Train Them
June 18, 2024Note: This blog post is based on the preprint “Transcendence: Generative Models Can Outperform the Experts That Train Them” by Edwin Zhang, Vincent Zhu, Naomi Saphra, Anat Kleiman, Benjamin L. Edelman, Milind Tambe, Sham Kakade and Eran Malach.
Generative models are trained to mimic the data they learn from, often created by human experts. While we may not expect models trained to imitate to outperform their creators, these models often surprise us by excelling in ways we never expected. How is it possible that machines trained to follow can end up leading the way? In our latest preprint, we delve into this phenomenon of transcendence, where generative models outperform the very data they learned from. We outline the conditions for such behavior, and set the stage for broader exploration into how AI may surpass human capabilities in fields like natural language processing, computer vision, and beyond.
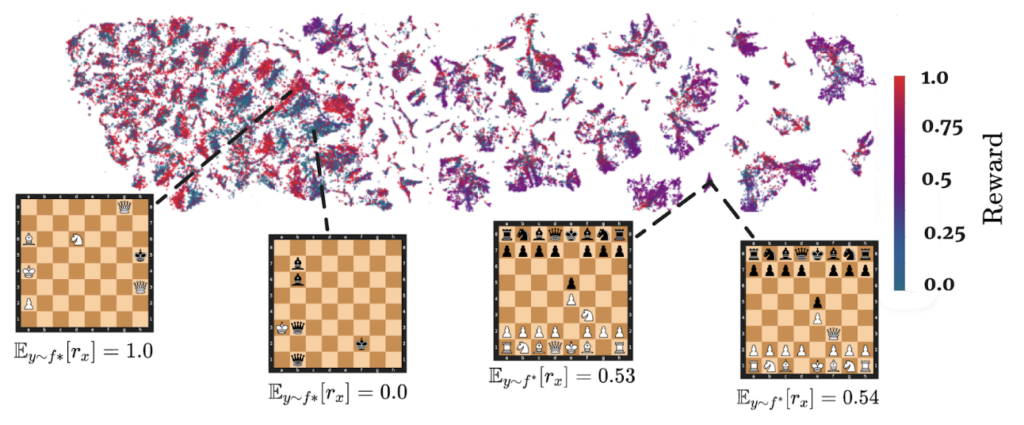
What is Transcendence?
Imagine two people, Ben and Shannon, playing chess in front of a huge auditorium. Shannon is a decent player with a 1400 Glicko-2 skill rating (the average player is rated around 1500), but Ben has never played chess before. Thankfully, the auditorium is packed with 1000-rated chess players who know how to play chess but are not very good, and they all want Ben to win. Every time Ben needs to play a move, each person in the audience shouts out their recommended move. Typically, the audience won’t agree – if Ben’s queen is attacked, some audience members might miss the danger and suggest a suboptimal move, but more of the audience members will be able to avoid the clear blunder. If Ben always listens to the majority of the audience, and plays the loudest recommendation, he is very unlikely to fall prey to the scattered blunders. Each audience member might call out a suboptimal move once or twice through the game – it is not uncommon to see several blunders in a game played by a 1000-rated player. However, if these lapses in judgment do not occur for the majority of the audience at the same time, Ben will be able to play better than any individual audience member. In fact, he would give Shannon a real run for her money.
This story demonstrates a key principle for gaining transcendence through majority voting, or wisdom of the crowd. In order to study this principle, we turn to chess—a constrained, well-understood game with a well-defined objective and a rich history of study. To identify transcendence, we choose some maximum rating and train a model on games where every player is below that threshold. We train several 50 million parameter autoregressive transformer decoders trained with next-token prediction (original training code taken from Karvonen). The chess games are represented as Portable Game Notation (PGN) strings (think 1. e4 e5 2. Nf3 Nc6 ….. 1-0). At no point was the model given information regarding the board state, rules of the game, player ratings, or any reward information during training. Yet as you can see in Figure 1, our model is able to recover important semantic information like the color of the player and the state of the game. You can learn more about the dataset, and the training code.
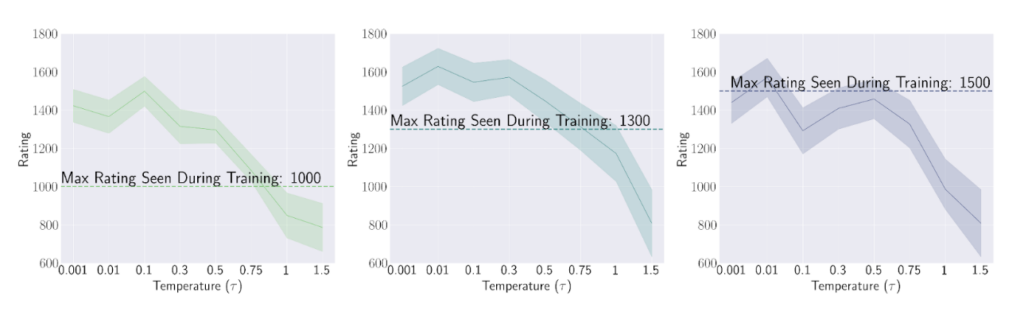
If the maximum rating seen during training is low, the model will only see games played by weak players. After the model is trained, we can accurately compute its chess rating by having it play several hundred games against Stockfish, a popular chess engine. As shown in Figure 2, Chessformer 1000 and Chessformer 1300, two chess models trained on data from players with maximal rating of 1000 and 1300 respectively, were able to transcend their training data, achieving significantly better chess rating compared to all the players in the dataset. However, Chessformer 1500, a model trained on players with rating below 1500, did not achieve transcendence at test time, reaching a chess rating similar to the players in the data. So what caused Chessformer 1000 and 1300 to transcend, and what held Chessformer 1500 back?
When does Transcendence happen?
We’ve identified several conditions necessary for transcendence in the constrained setting of chess. One of these crucial conditions is just choosing the most likely moves, or low-temperature sampling. By sampling from many weak experts, like 1000-rated players, and playing the ‘majority vote’ on each move at test time, we can use the ‘wisdom of the crowd’ to avoid mistakes, and thus play as a ‘clean’ 1500-rated player, mitigating the noise of any scattered mistakes from individual experts. As we want to harness the ‘wisdom of the crowd’ at test time, it is clear that a transcending model must be configured with a low temperature, which plays the majority vote on every move.
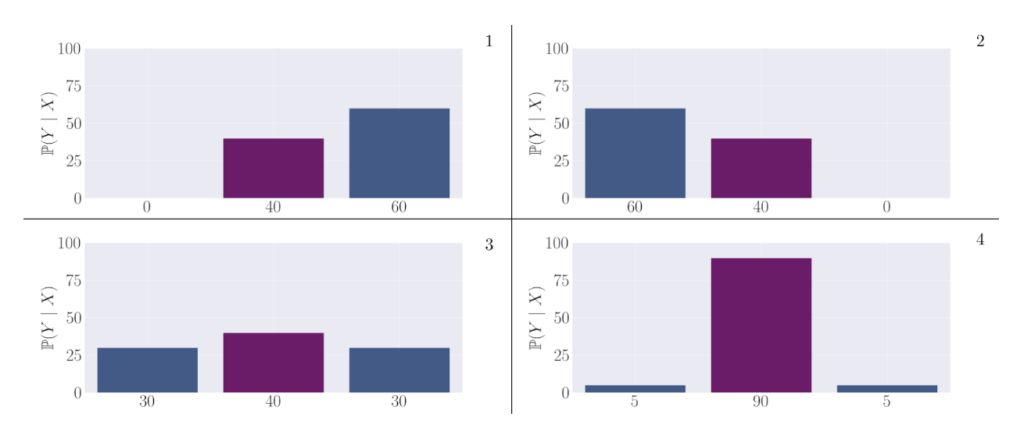
To build intuition for the primary mechanism of transcendence that we explore in this work, we give the following toy progression of distributions to clearly illustrate how low-temperature sampling can induce transcendence through majority voting. Here, the middle purple action represents the correct, high-reward output, while the left and right actions are low-reward, suboptimal outputs. We plot the probability of each output as a label on the x-axis. (1) The first expert output distribution: Although it puts non-negligible mass on the purple, high-reward action, it still samples a low-reward action the majority of the time; (2) The second expert output distribution: Symmetric to the first expert, it also puts non-negligible mass on the purple, high-reward action. However, it samples a low-reward action the majority of the time on the right; (3) By taking the average of the first and second experts, we observe that this distribution now puts the majority of mass onto the correct action; (4) Finally, by setting the temperature to be <1, more weight is shifted towards the high probability action, leading to a gain in the expected reward.
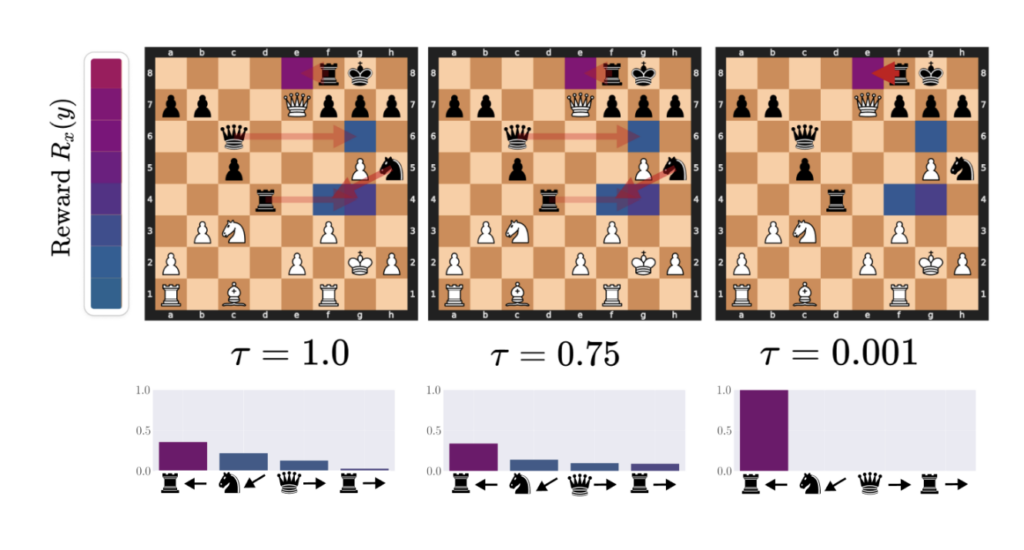
In Figure 4, we can now give an actual example of this phenomenon occurring in chess by visualizing the denoising effects of low temperature on the action distribution. Specifically, this is an example of ChessFormer shifting probability mass towards the high reward move of trapping the queen with the rook as the temperature (𝜏) decreases. Opacity of the red arrows represent the probability mass given to different moves, while the color of the square represents the reward that would be given for taking the action that moves the given piece to that state. Purple here is high reward, while blue is low. For more visualizations, please see our paper.
Conclusion
Our work introduces and defines transcendence, as well as some of the necessary conditions for it to occur in the specific constrained setting of chess – namely, dataset diversity and low-temperature sampling. While our work is the first systematic study of this phenomenon, we note that transcendence has also been previously demonstrated on lichess by the Maia chess models, a family of generative convolutional models trained to imitate human data. In fact, the primary inspiration for our work was the observation that Maia 1, trained on just players rated from 1100-1200, is able to consistently achieve around 1500 rating during evaluation. While our work provides a foundation for understanding and achieving transcendence, several important avenues for future research remain. Future work may investigate transcendence and its causes in domains and contexts beyond chess, such as natural language processing, computer vision, and robotics, to understand the generalizability of our findings. Additionally, our theoretical framework assumes that game conditions at test time match those seen during training; to extend our findings to cases of composition or reasoning, we must forgo this assumption.