
This blog is adapted from
Interpretable deep learning for deconvolutional analysis of neural signals
Mechanistic Interpretability: A Challenge Common to Both Artificial and Biological Intelligence
April 14, 2025In neuroscience, the past decade has witnessed major advances in our ability to record activity from the brain at both larger and finer scales. And yet, a mechanistic theory linking computation to intelligent behavior remains elusive. By “mechanistic theory,” we mean explanations, in terms of human-understandable concepts, of the activity of neurons and how they relate to an agent’s behavior. Mechanistic theories seem to have become even more elusive as experimental research has been shifting from highly-structured research, where experimentalists can exercise explicit control over experimental variables, to naturalistic ones in freely-behaving animals, where implicit, exogenous variables drive neural activity.
What implicit factors drive neural activity in natural settings?
In such naturalistic settings, can we develop human-interpretable AI models to explain neural activity and behavior? Two challenges pose themselves. First, AI models rely on latent, hidden representations of experimental data. What latent space ought we to embed neural data in? We propose aligning this latent space with human-understandable variables such as space and time.
The second challenge is the polysemanticity of biological neurons: neurons typically encode multiple human-understandable concepts in superposition. Thus, a suitable interpretable AI model ought to be able to disentangle these overlapping components.
In new research published March 11 in Neuron we have developed a family of interpretable artificial neural networks, convolutional sparse auto-encoders specifically, to explain neural activity in structured settings in terms of human-understandable components. This work builds upon several years of research at Harvard, by the CRISP group and collaborators, aimed at bridging the gap between black-box deep neural networks and explicit mechanistic models. Incidentally, and subsequent to our work, sparse auto-encoders have become a popular approach to interpret large language models.
Taming neural complexity with deep learning: an interpretable method for decomposing neural activity
Imagine yourself in a Boston Symphony Orchestra performance, closing your eyes, and trying to guess which set of instruments are playing in any particular snippet of time: some might be always present in the background, while others might have sparser contributions to the musical piece. This might be an accessible task to a highly trained musician, but a nearly impossible task for someone without a musical background.
This is a point source detection problem, in which the multiple sources of a complex signal are located. The brain is somewhat like an orchestra: a large ensemble of cells of different types whose coordinated yet heterogeneous activity patterns generate (mostly) harmonious behavior.
Building on this analogy, our multidisciplinary team from the Uchida and Murthy Labs and the CRISP group has developed DUNL (Deconvolutional Unrolled Neural Learning), described in the new Neuron paper. This novel framework addresses one of neuroscience’s biggest challenges: understanding how neurons encode information when they respond to multiple factors simultaneously, showing mixed selectivity in single neurons and across neural populations with complex, overlapping activity patterns.
DUNL enables researchers to break down neural activity into interpretable components, working with single-trial and single-neuron activity rather than relying on averaged responses. While traditional methods like principal component analysis and non-negative matrix factorization find lower dimensional representations capturing global trends, they cannot decompose neural signals into individual local components at the single-neuron level. This limitation is particularly problematic when studying neurons exhibiting mixed selectivity, such as dopamine neurons that encode both value and salience of external stimuli.
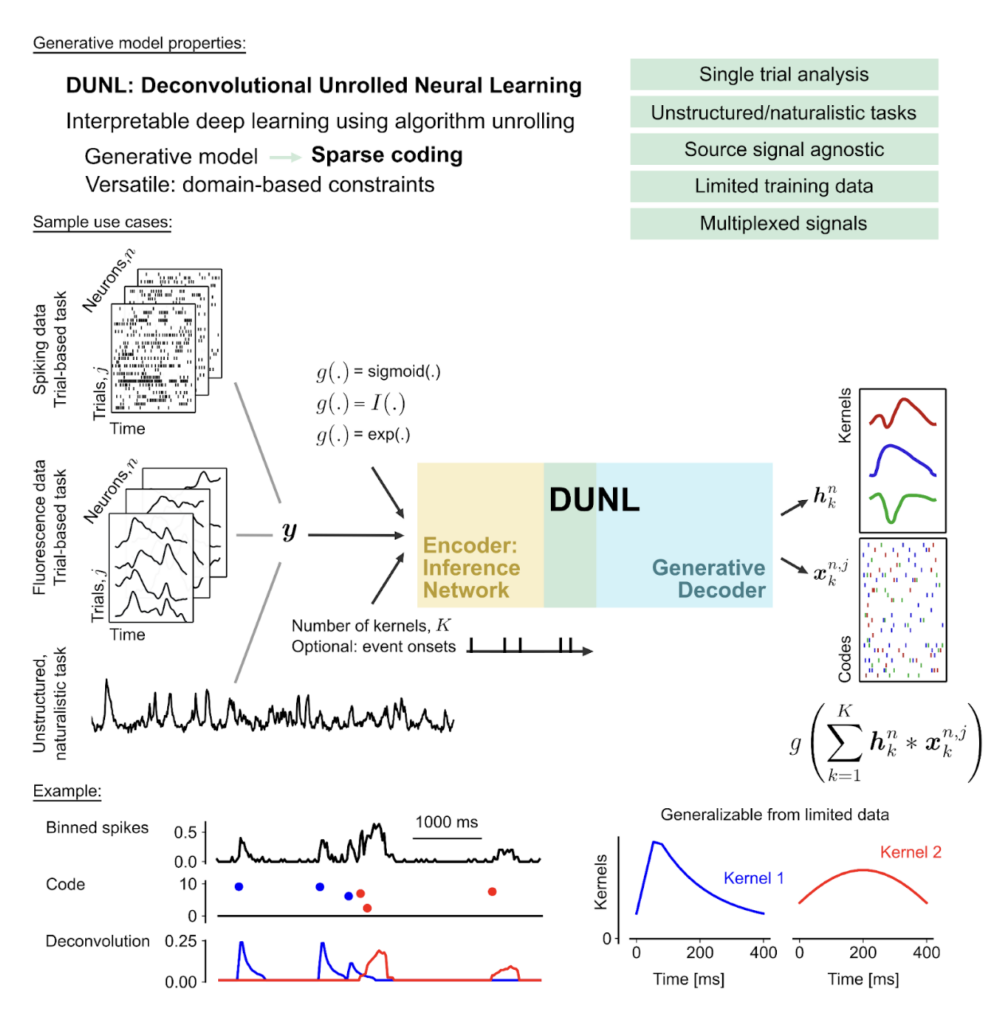
A versatile and effective framework
DUNL combines deep learning with interpretability through algorithm unrolling, transforming an optimization process into a structured neural network constrained by a convolutional generative model. In practice, DUNL models mean neural activity as a sum of convolutions between impulse-like responses to different events (kernels) with a vector of occurrence times and amplitudes (sparse codes). DUNL provides a framework that accounts for the statistical properties of data when designing deep learning models for binary or count data, such as neural spiking activity.
We’ve demonstrated DUNL’s capabilities across diverse neural data types: decomposing dopamine neuron responses into salience and value components, performing simultaneous event detection in thalamic neurons during whisker stimulation, identifying distinct response patterns to stochastic odor pulses in the olfactory cortex, and characterizing heterogeneous dopamine axonal signals across the striatum during naturalistic experiments. This versatility shows DUNL’s effectiveness in both structured and unstructured settings.
DUNL, as well as sparse auto-encoders used to explain the cells’ activity, enable a form of mechanistic interpretability that we refer to as activation-level interpretability. This form of interpretability typically requires a human in the loop to label components/features extracted. Are these really the ground-truth components/features?
Looking forward: the case for interpretable tasks
Moving forward, we propose that mechanistic interpretability in both fields may benefit from adopting tasks that are neither completely unstructured nor too structured: mathematically grounded activities like puzzles, games, and play. Such tasks, being objective and evolutionarily conserved, can help narrow down the space of algorithms that artificial and biological organisms employ, potentially giving us a firmer grasp on mechanistic theories of intelligence.
Conclusion
Our ongoing work using sparse auto-encoders to analyze neural computation in naturalistic environments parallels current research in LLM interpretability, highlighting the growing convergence between neuroscience and AI in the quest for mechanistic understanding. This synergy between fields may hold the key to developing more comprehensive theories of intelligence, both artificial and biological.