
Anything but SGD: Evaluating Optimizers for LLM Training
July 12, 2024LLM training can be expensive, so we want to make sure that we are using efficient optimizers. In our recent paper we perform a rigorous study of a variety of optimizers to try to see what works best (among diagonal preconditioning methods). To jump to the punchline, we find that they are all fairly similar except for SGD, which is notably worse.
Zooming in, we find that Adam, Lion, Adafactor (with momentum), and Signum (signed SGD with momentum) all achieve similar performance and robustness to hyperparameters across a variety of model sizes and architectures. But, standard SGD with momentum is consistently worse in terms of optimal performance and substantially worse in terms of robustness to hyperparameters. We did 1D ablations across each hyperparameter for each algorithm and find surprisingly similar behavior across all the optimizers we test except for SGD.
To push this insight to the limits we study some even simpler adaptive optimizers that lie on a spectrum between SGD and Adam. We find that as long as we adapt the learning rates for the output layer and the layer norm parameters, we can freeze the other learning rates and nearly recover the performance of Adam! This gives some insight into what sort of adaptivity is really necessary used when optimizing a language model.
Performance and stability of various optimizers
Setup
We train language models on C4 dataset tokenized with the T5 tokenizer and report results in terms of validation loss. We will evaluate algorithms both in terms of the loss achieved by the best hyperparameters (performance) as well as the robustness across values of the hyperparameters (stability).
Token Counts: For all models, we use a batch size of 256 and sequence length of 512 (as in Wortsman et al.). We default to training models for the approximately chinchilla optimal number of tokens that is approximately 20 times the number of parameters. Explicitly, this means for the 150m models we train for 25k steps or 3.3b tokens. The 300m models are trained for 50k steps, the 600m models are trained for 100k steps and the 150m-long models are also trained for 100k steps.
For details about our architecture and default hyperparameters, refer to our paper. First, we will consider the performance and stability with respect to learning rate, as it is one of the most crucial hyperparameters in practice.
Learning rate stability
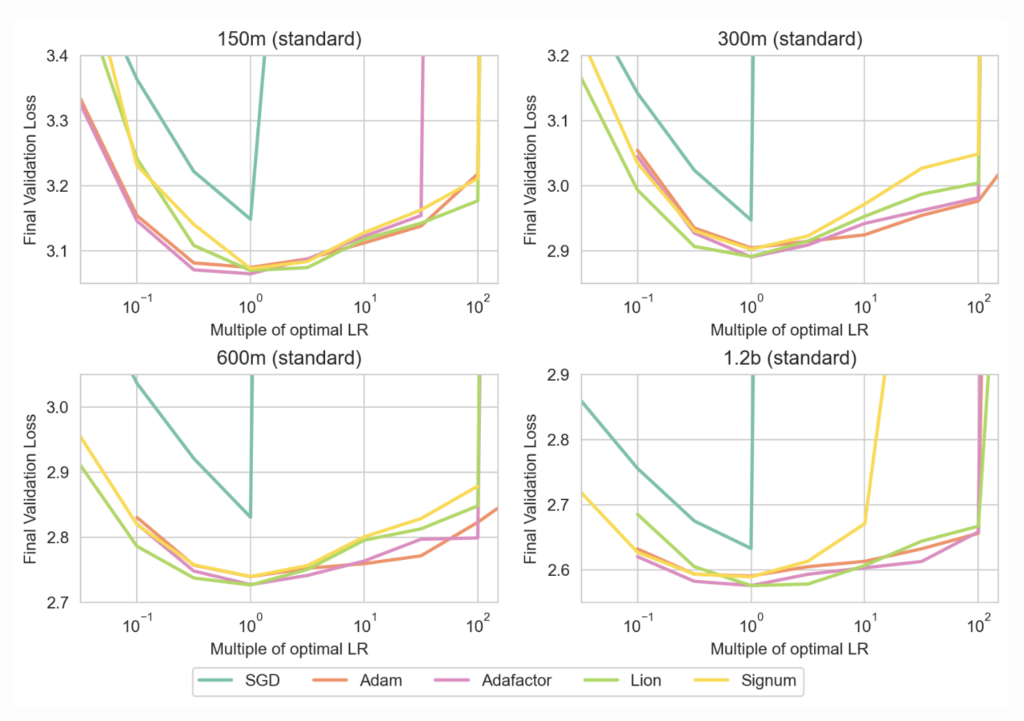
The figure above shows the performance of various algorithms including Adam, Lion, Adafactor[1], Signum and SGD with momentum on language modeling. It can be seen that, all the optimizers, except for SGD, have similar performance across a range of learning rates, for various model scales. This figure shows that, with respect to learning rate stability, there is no clear better choice among these optimizers (except for SGD).
Moreover, from a practical standpoint, Lion and Adafactor have significantly reduced memory requirements as compared to Adam, and thus are preferable from an efficiency viewpoint.
Stability of other hyperparameters
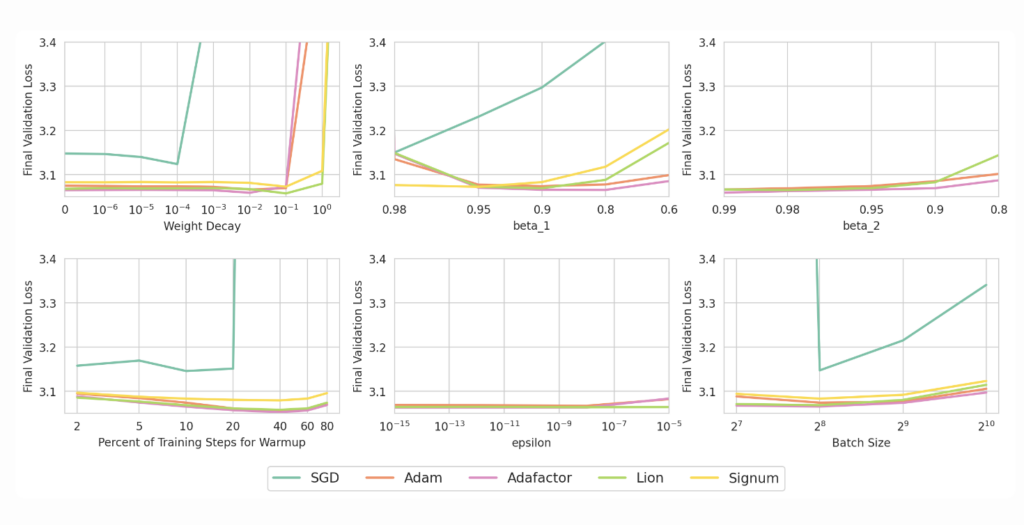
Given the optimal learning rate from the previous sweeps, we further compare the stability of these optimizers with respect to various other hyperparameters such as weight decay, momentum (𝛽1), number of warmup steps, and regularization constant (𝜖). We find that:
1. The stability of all these optimizers (except SGD) is similar with respect to these hyperparameters.
2. The default choices, such as $\beta_1 = 0.9$ or $\epsilon = 10^{-8}$, are usually close in performance to the optimal choices.
Can we improve SGD’s performance and stability?
Given our previous ablations, we sought a better understanding of the role of preconditioners for adaptive optimizers to achieve both performance and stability. More specifically, we study which parameters of the network need adaptivity, and whether we can improve SGD’s performance and stability with minimal modifications.
We studied an optimizer that we refer to as Adalayer, which is a “layer-wise” variant of Adam[2]. Adam stores the full second moment matrix for each layer, and Adalayer instead stores a single scalar averaging over “blocks” of parameters. Adalayer reaches similar performance and stability compared to Adam while being more amenable for analysis (eg. studying effective learning rates over different blocks).
It turns out that most language model parameters can be trained with SGD. We trained language models using a ‘hybrid’ optimizer where we use Adalayer on only the last layer logits[3] and LayerNorm blocks, and we use SGD for the rest of the network. This achieves performance on-par with Adalayer on the entire network or Adam, and also recovers stability of learning rates which SGD did not have previously.
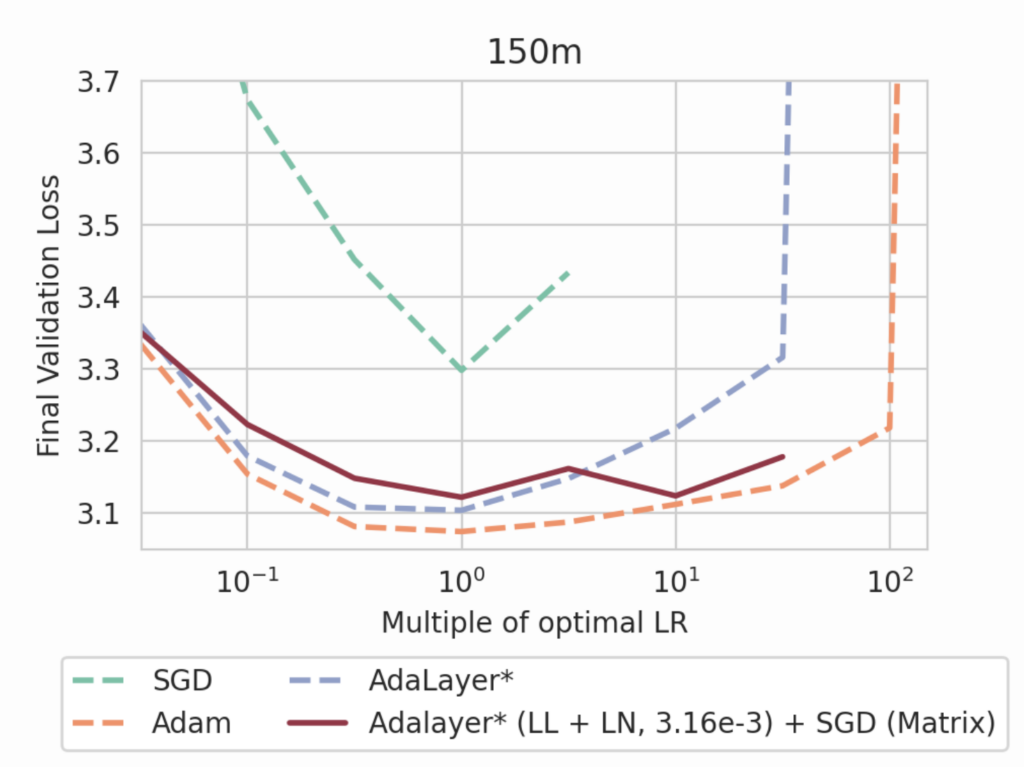
This is a surprising result, because the last layer and LayerNorm blocks form a small fraction of the model’s parameters. However, our results indicate that most of the benefits of adaptive optimizers arise from their treatment of these two sets of parameters. In our paper, we also observed that adding adaptivity to only one of these two sets of parameters does not recover the same performance and stability.
See our paper for several more investigations, including studying the effective learning rates of parameter blocks in Adalayer, training models with a “frozen” version of Adalayer (where learning rate ratios are fixed from initialization), and performing the same experiment as above using Adafactor instead of Adalayer.
Conclusion
So, what is the takeaway for practitioners? Well, it seems that since the algorithms other than SGD are largely similar, other considerations like speed and memory should take precedent. For example, all of Lion, Adafactor, and Signum have significantly less memory overhead than Adam (no full-rank second moment estimates to keep track of), and Adalayer even more so, although it sacrifices some performance. Perhaps some of these lighter optimizers can replace Adam as the workhorse of LLM optimization.
Note: This blog post is based on “Deconstructing What Makes a Good Optimizer for Language Models” by Rosie Zhao, Depen Morwani, David Brandfonbrener, Nikhil Vyas, and Sham Kakade.
- We add back momentum to Adafactor for all of our experiments, see paper for details.[↩]
- Here we aren’t introducing a new optimizer and we use Adalayer only for investigating the role of preconditioning in Adam. Coarser layer-wise/block-wise variants of Adam have been studied extensively in the literature (see Related Works in our paper).[↩]
- We treat the set of weights feeding into each logit of the last layer as its own block, which is crucial for Adalayer’s performance and stability.[↩]