
What Data Assumptions Come With Your SAE?
May 08, 2025Sparse Autoencoders (SAEs) are popular tools to interpret neural networks. We show that SAEs are inherently biased toward detecting only a subset of concepts in model activations shaped by their internal assumptions, highlighting the need for concept geometry-aware design of novel SAE architectures.
Sparse Autoencoders (SAEs) are emerging as central tools in the interpretability of neural networks. By learning a sparse, overcomplete latent representation of hidden activations, SAEs offer a pathway to recover latent directions that align with human-understandable concepts. These sparse latents have been shown to activate for specific objects in images, discrete structures in text, and even functional motifs in biological sequences. Yet, a central question remains:
Do SAEs truly uncover all relevant concepts used by a model, or are they inherently biased toward detecting only a subset of features shaped by their internal assumptions?
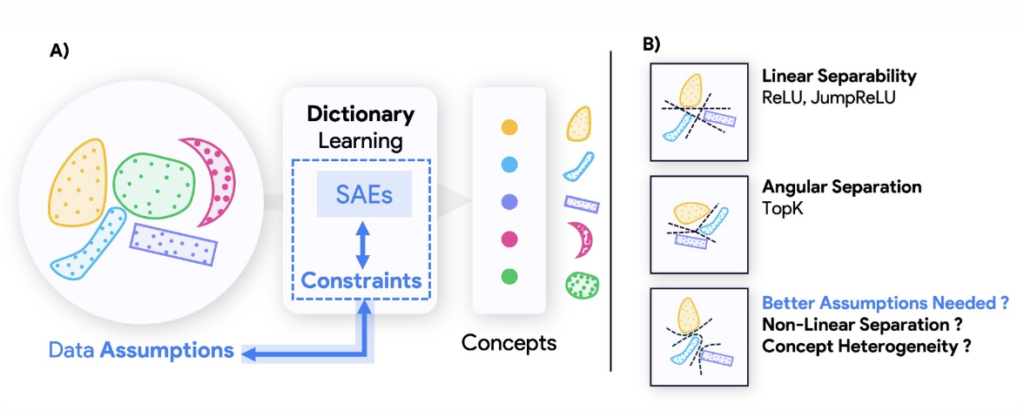
This question reframes the role of SAEs: rather than acting as passive lenses onto model representations, their architectural constraints impose inductive biases that determine which concepts can be seen. As we show in this work, these biases take the form of geometric constraints encoded into the encoder’s nonlinearity, and different architectures correspond to different partitions of the representation space. Thus, switching the SAE architecture may reveal entirely new concepts—or obscure ones that were previously visible.
We make this idea concrete by recasting SAE training as a bilevel optimization problem. Within this framework, the encoder enforces an inner constraint through a projection nonlinearity, while the outer optimization solves a dictionary learning problem. This formalism not only unifies various existing SAEs under a common lens, but also makes explicit the duality between concept geometry in data and projection geometry in the encoder. Our findings imply that the monosemanticity and fidelity of an SAE are fundamentally determined by the alignment between these two structures.
Overview
Sparse Autoencoders (SAEs) are widely used to interpret neural networks by identifying meaningful concepts from internal representations. Different SAEs, which share the objective of discovering concepts, have typically been compared using reconstruction-sparsity plots. We show that this metric is insufficient to compare SAEs on their ability to extract concepts. This is because SAEs are not guaranteed to uncover every concept a model relies on. Rather, different architectures implicitly encode different assumptions about how concepts are structured, which affects which ones can be recovered.
In this work, we present a unified framework for SAEs as solutions to bilevel optimization problems. In this formulation, the encoder performs an orthogonal projection onto an architecture-specific constraint set, while the decoder reconstructs input representations from the sparse latent code. This interpretation allows us to understand each SAE architecture as enforcing a specific form of geometric inductive bias. These biases define the structure of the receptive fields of latent units and consequently shape the kinds of concepts that can be reliably extracted.
We evaluate this theoretical framework across a spectrum of settings, ranging from controlled synthetic setups to real activations from vision transformers and formal language models. In doing so, we identify two geometric properties commonly observed in model representations: nonlinear separability and heterogeneous intrinsic dimensionality. When these properties conflict with a given SAE’s inductive biases, the SAE systematically fails to recover relevant concepts. To address this, we introduce SpaDE, a new SAE architecture that explicitly incorporates both properties. Our results show that SpaDE reliably discovers previously hidden concepts, emphasizing the importance of aligning encoder assumptions with data geometry.
SAE Recap and the Bilevel Optimization Framework
SAEs can be seen as an approximation to classical sparse dictionary learning, where the goal is to reconstruct each datapoint $\mathbf{x} \in \mathbb{R}^d$ from a sparse combination of learned dictionary elements. Specifically, the classical objective is:
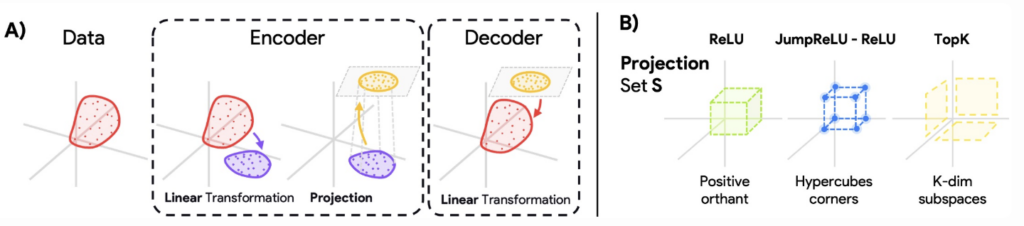
$$ \min_{\mathbf{z} \ge 0, D \in \mathcal{B}} \sum_{\mathbf{x}} \|\mathbf{x} – D \mathbf{z}\|_2^2 + \lambda R(\mathbf{z}), $$ where $\mathbf{z} \in \mathbb{R}^s$ is a sparse code, $D \in \mathbb{R}^{d \times s}$ is the learned dictionary, and $R(\mathbf{z})$ is a sparsity-promoting regularizer (typically $\ell_1$ or $\ell_0$ norm). SAEs approximate this framework by replacing the inner sparse optimization with a feedforward encoder: $$ \mathbf{z} = f(\mathbf{x}) = g(W^\top \mathbf{x} + \mathbf{b}_e), \quad \hat{\mathbf{x}} = D \mathbf{z} + \mathbf{b}_d, $$ where $W, D \in \mathbb{R}^{d \times s}$ and $g(\cdot)$ is a sparsity-inducing nonlinearity. The encoder can be understood as applying a linear transformation followed by an orthogonal projection onto a constraint set $S$. This brings us to the key insight of the paper: many encoders can be rewritten as projection nonlinearities. That is, the nonlinearity $g(\cdot)$ is equivalent to solving the following inner optimization: $$ \Pi_S \{ \mathbf{v} \} = \arg\min_{\boldsymbol{\pi} \in S} \|\boldsymbol{\pi} – \mathbf{v} \|_2^2, $$ where $\mathbf{v} = W^\top \mathbf{x} + \mathbf{b}_e$ and $S$ is an architecture-specific constraint set. For example:
- ReLU SAE projects onto $S = \{ \mathbf{z} \in \mathbb{R}^s : \mathbf{z} \ge 0 \}$,
- TopK SAE projects onto $S = \{ \mathbf{z} \in \mathbb{R}^s : \mathbf{z} \ge 0, \|\mathbf{z}\|_0 \le k \}$.
This structure leads directly to the following bilevel optimization formulation: $$ \min_{D,\, \mathbf{z} \ge 0} \sum_{\mathbf{x}} \|\mathbf{x} – D\mathbf{z}\|_2^2 + \lambda R(\mathbf{z}) \quad \text{s.t.} \quad \mathbf{z} = f(\mathbf{x}) \in \arg\min_{\boldsymbol{\pi} \in S} F(\boldsymbol{\pi}, W, \mathbf{x}), $$ where the inner minimization reflects the encoder architecture via the projection set $S$ and objective $F$ (typically $F(\pi, W, \mathbf{x}) = \|W^\top \mathbf{x} + \mathbf{b}_e – \pi\|_2^2$). This general formulation allows us to define an SAE as a constrained solution to sparse dictionary learning where the constraint is enforced by the encoder’s geometry. As a result, the performance of an SAE depends critically on whether its projection set $S$ matches the geometry of the underlying data.
Implicit Assumptions in SAEs
A Sparse Autoencoder is successful only to the extent that the organization of concepts in data aligns with its architectural priors. This alignment is not incidental—it is imposed by the geometry of the encoder’s projection set, which defines the receptive fields of the resulting latent units. In the case of ReLU and JumpReLU SAEs, these receptive fields are half-spaces—hyperplanes that slice the input space along fixed linear boundaries. Consequently, these architectures assume that each concept is linearly separable from others.
TopK SAEs make a different assumption: they rely on angular separation. Because only the top $k$ features are activated based on magnitude, the receptive field for each latent forms a region defined by competitive selection—essentially a hyperpyramid or wedge. This implies that each concept must reside within its own angular sector in the activation space.
These assumptions are not merely implementation details; they constitute implicit data priors. As shown in Theorem 4.1 of the paper, the projection set $\mathcal{S}$ and its associated structure directly determine what kinds of concepts are visible. If a concept lies outside the geometric bounds defined by the SAE’s projection set, the latent unit will never activate for it. The encoder thus acts as a filter: certain geometries pass through; others are entirely suppressed.
Crucially, real-world data seldom conforms to such rigid structures. As the literature on interpretability and latent analysis has shown, concepts in neural networks may have nonlinear or manifold-based boundaries, or occupy heterogeneous subspaces of variable intrinsic dimension. Under these conditions, an SAE with mismatched assumptions will either produce uninterpretable latents or completely miss salient structure.
Geometry and Heterogeneity in Concept Space
To probe the optimality of the geometric assumptions encoded by various SAEs, we examine two properties frequently observed in both synthetic and real model representations:
First, many concepts are nonlinearly separable. They may not be distinguishable using simple half-space partitions. Instead, their boundaries may depend on magnitude (e.g., in radial space), structure (e.g., hierarchical labels), or periodicity (e.g., weekdays). The literature has demonstrated that concepts such as onion features, circularly-embedded date features, or position-dependent linguistic attributes fall into this category.
Second, concepts often exhibit heterogeneous intrinsic dimensionality. Some concepts—such as binary truth features—can be expressed in a single latent dimension. Others—like role-playing narratives or temporal sequences—may require high-dimensional subspaces for faithful representation. A fixed-$k$ model like TopK cannot adapt its latent allocation to match these differences.
These two properties lead to well-characterized failure modes in common SAEs:
- ReLU and JumpReLU fail when linear separability is violated.
- TopK fails when latent dimensionality varies across concepts, due to its fixed sparsity budget.
As shown in Table 3 of the paper, no existing SAE architecture simultaneously accommodates both nonlinear separability and concept heterogeneity. This highlights the need for architectures whose projection sets allow both: curved or magnitude-sensitive boundaries, and adaptive sparsity across examples.
Designing SpaDE
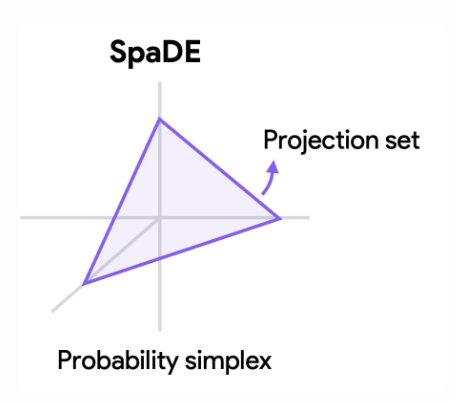
To close the gap left by existing architectures, we introduce SpaDE: the Sparsemax Distance Encoder. This model modifies the encoder design in two key ways:
1. Distance-Based Pre-Activation Instead of inner products, SpaDE uses squared Euclidean distances between inputs and learned prototypes: $$ d(\mathbf{x}, W)_i = \|\mathbf{x} – \mathbf{w}_i\|_2^2 $$ These distances allow the encoder to capture radial or magnitude-sensitive structures in concept space—something that existing (ReLU, JumpReLU and TopK) SAEs with linear transforms cannot.
2. Sparsemax Over the Probability Simplex The resulting distances are transformed using sparsemax: $$ \mathbf{z} = \mathrm{Sparsemax}(-\lambda \cdot d(\mathbf{x}, W)), $$ where $\lambda$ controls the sparsity level and $\mathrm{Sparsemax}$ performs a projection onto the probability simplex: $$ \Delta_s = \left\{ \pi \in \mathbb{R}^s \,:\, \sum_i \pi_i = 1,\, \pi_i \ge 0 \right\}. $$ The simplex allows for adaptive sparsity: some inputs may activate one latent (for low-dimensional concepts), others may activate many (for diffuse, high-dimensional concepts). This yields a flexible, data-aware encoder that can adapt to both nonlinear separability and heterogeneous dimensionality.
Formally, the receptive fields of SpaDE units are unions of convex polytopes localized around the prototype $\mathbf{w}_i$, and shaped by the local geometry of the sparsemax projection as well as the positions of other prototypes $\{\mathbf{w}_j\}$ in the vicinity (see Appendix D.2.3 in the paper). Unlike half-spaces, these polytopes can warp and bend to match complex data manifolds.

Additionally, SpaDE behaves like a locally adaptive ReLU SAE. In fact, its encoder can be rewritten as a ReLU activation with an input-dependent affine transform: $$ \mathrm{Sparsemax}(-\lambda d(\mathbf{x}, W)) = \mathrm{ReLU}(A(\mathbf{x}) \mathbf{x} + \mathbf{b}(\mathbf{x})), $$ where $A(\cdot)$ and $b(\cdot)$ are piecewise-constant functions, defined using the prototypes nearest to $\mathbf{x}$. This result reveals that SpaDE generalizes traditional ReLU SAEs, adding the ability to localize each latent’s receptive field to a flexible, concept-aligned region of space.
Empirical Validation of SAE Limitations
Using synthetic gaussian clusters data, we show that ReLU and JumpReLU fail to capture concepts that are not linearly separable: they show low F1 scores (measures specificity and selectivity of SAE latents to a concept) on nonlinearly separable concepts.
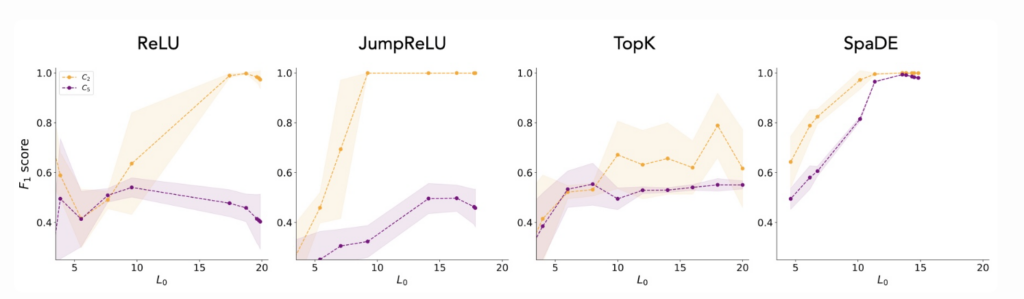
TopK struggles to capture heterogeneous concepts with different intrinsic dimensions, due to the choice of a fixed sparsity level K. For concepts whose dimension exceeds the choice of K, TopK SAE shows high mean squared error (MSE).
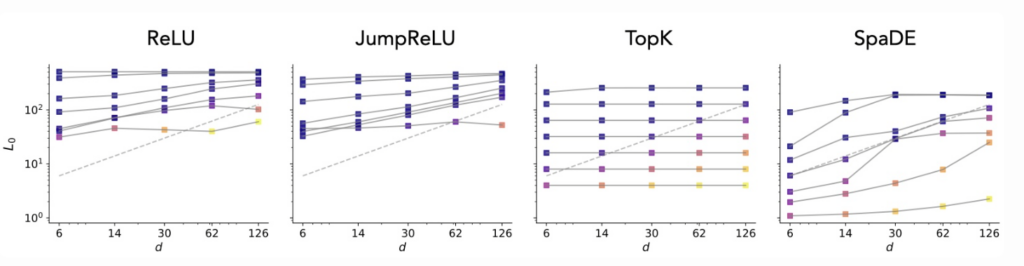
These limitations of ReLU, JumpReLU and TopK SAEs also show up in more realistic experiments- with nanoGPT trained on formal languages and DINOv2 on ImageNette, a 10-class subset of ImageNet. The ability of SpaDE to overcome these limitations is majorly due to its ability to tile concept manifolds in model activations even in high-dimensional spaces, as seen below (do read the paper for detailed results and analysis):


Feature attribution maps for concepts learnt by SpaDE in vision (DINOv2 on ImageNette) show qualitatively interesting concepts!
Overall, our results emphasize that there may not be a single best SAE architecture for all contexts unless the architecture explicitly integrates a sufficient set of data properties relevant to the specific problem. This suggests a shift in focus from using generic SAEs to tailoring their design based on prior knowledge about the underlying data geometry.