
This blog is adapted from
To Backtrack or Not to Backtrack: When Sequential Search Limits Model Reasoning
To Backtrack or Not to Backtrack: When Sequential Search Limits Model Reasoning
April 25, 2025Understanding whether backtracking enhances the reasoning ability of large language models helps us build smarter AI systems. This research clarifies when and how backtracking works best, guiding future training strategies for powerful reasoning models.
In recent months, large language models (LLMs) have impressed the world with their remarkable reasoning abilities—solving competition-level math problems and even mimicking human-like thought processes. One particular behavior that has captured the attention of the research community is known as backtracking. At its core, backtracking allows models to explicitly correct their mistakes by “thinking out loud,” exploring alternative paths, and refining their solutions using long chains of thought (CoT). The appeal is clear: making and correcting mistakes is fundamental to human intelligence, so enabling LLMs to do the same feels both intuitive and powerful.
Yet, despite its growing popularity, a critical question remains largely unanswered: Is backtracking truly the most efficient way to use computational resources at test time? Could simpler methods—like parallel sampling, where the model generates multiple solutions simultaneously and selects the best one—yield better results?
The answer isn’t obvious for two key reasons. First, autoregressively generating long CoTs is computationally expensive, as the cost scales quadratically with the context length due to the attention mechanism. Second, backtracking implicitly assumes the model must make mistakes first before correcting them. But what if the model could have avoided the mistake in the first place? By encouraging backtracking, we might be locking the model into a suboptimal strategy—repeating errors just to fix them later—when, ideally, it could have reasoned more efficiently from the start.
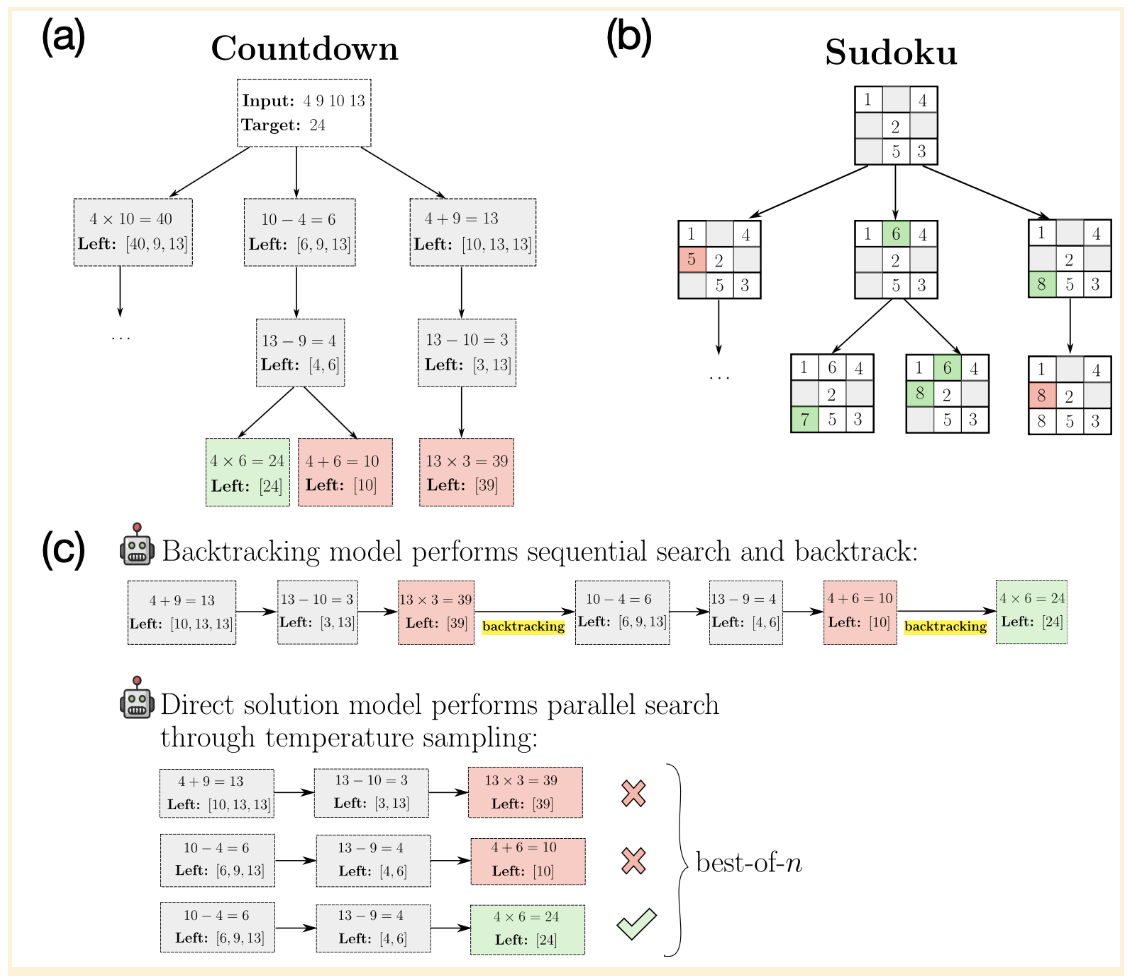
To investigate this dilemma—to backtrack or not to backtrack—we turned to two logic-heavy games: CountDown and Sudoku. These games serve as ideal testbeds for examining the computational trade-offs between sequential reasoning (via backtracking) and parallel solution strategies (via best-of-N sampling). In this controlled setting, our goal is to better understand when, how, and why backtracking is actually effective.
Is Backtracking the Holy Grail for Smarter Models?
In our experiments, we train two fundamentally different types of models. The first, backtracking models, learn to perform explicit search using Chain-of-Thought (CoT) reasoning. In other words, they “think out loud,” exploring different solution paths and backtracking when they reach a dead end. The second type, direct solution models, skip explicit search altogether and learn directly from correct solutions (see illustrations above). The core question we aim to answer is: given equal computational resources at test time, which model performs better?
Backtracking vs. Direct Solutions
Surprising Insights from Our Experiments
For CountDown, we create 500,000 puzzles and train a backtracking model (17 million parameters) using serialized Depth-First Search (DFS) traces. To scale test-time compute for the backtracking model, we allow it to generate reasoning chains of varying lengths and evaluate its accuracy on 200 unseen test problems. We also train a direct solution model of the same size, using only the correct solutions. At test time, we scale its compute by performing parallel sampling at temperature 0.7 and selecting the best result from Best-of-N. By equating test-time compute—measured in FLOPs—we compare the performance of the two models. Unexpectedly, the backtracking model underperforms the direct solution model across all compute budgets.
For Sudoku, we repeat the same experimental setup. We generate data from approximately 3 million puzzles, training backtracking models on DFS traces and direct solution models on correct solutions only. In stark contrast to CountDown, the backtracking model here outperforms the direct solution model. The deeper search trees and inherently sequential nature of Sudoku make backtracking highly advantageous, as models trained explicitly on structured search paths achieved significantly better performance than those relying on parallel sampling.

Most importantly, this contrast highlights a key insight: backtracking is not inherently better or worse—it depends heavily on the structure and demands of the task.
What Exactly Goes Wrong with CountDown Backtracking Model?
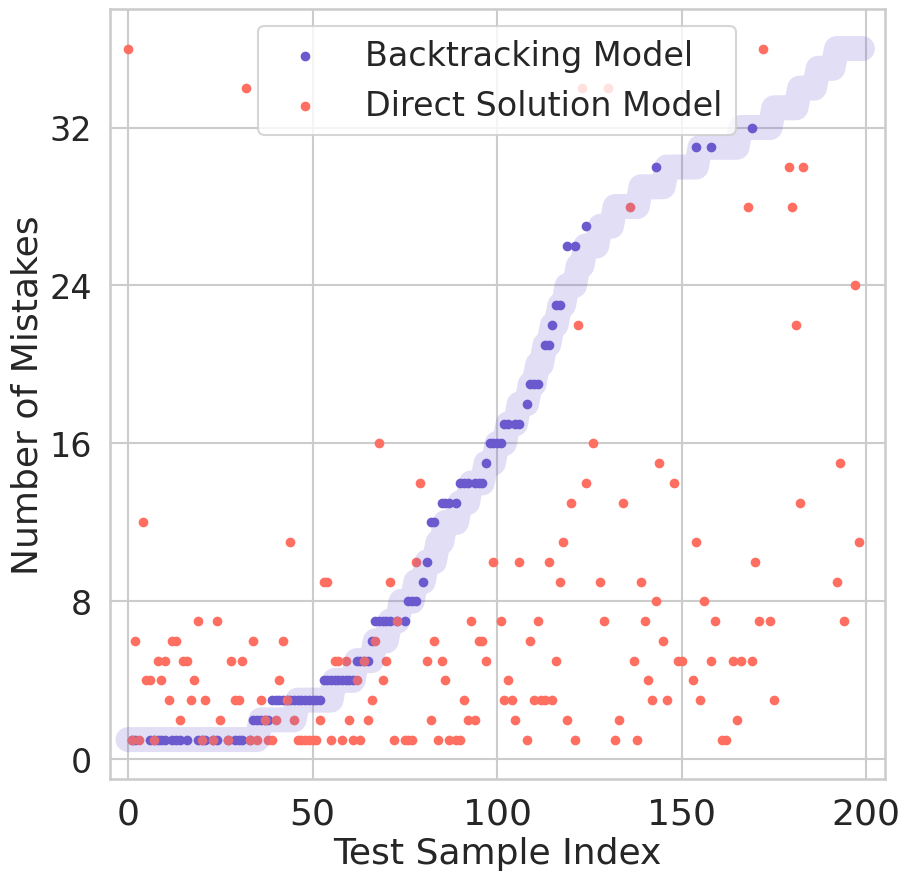
Identifying Two Pitfalls of Backtracking
Why does the backtracking model struggle with CountDown? Our analysis reveals two critical issues.
First, backtracking models make more mistakes. By explicitly training on handcrafted search traces (DFS), we enable backtracking behavior—but at a cost. These traces reinforce a specific search strategy, teaching the model to follow a prescribed search order. In contrast, the direct solution model learns only from correct solutions and is free to explore the search space in its own way. In CountDown, this flexibility proves beneficial: the direct solution model learns a more efficient search strategy and makes fewer mistakes—that is, it visits fewer incorrect leaf nodes—before arriving at the correct solution.

Second, backtracking models talk more but think less. CoT training requires models to output every reasoning step, which encourages verbosity. Instead of reasoning internally, the model outputs tokens for every reasoning step rather than “thinking” silently. This verbosity reduces test-time compute efficiency. However, in CountDown, we show that the backtracking model is capable of reasoning one step ahead implicitly, without degrading performance.
Motivated by these two observations, we experiment with two improved versions of the backtracking model.
Improving Backtracking Performance
We introduce two modifications to the backtracking model to address its limitations. The first, the Mix-backtracking model, is trained on a diverse set of search strategies—a mixture of breadth-first and depth-first traces. This diversity allows the model to learn a broader range of search behaviors, reducing its reliance on any single prescribed pattern. The second modification, the Think-backtracking model, aims to reduce verbosity by skipping one step in the DFS trace during training. This encourages the model to internalize part of the reasoning process, effectively “thinking” without explicitly outputting every step.
In Figure 5, we compare these two backtracking variants to the original backtracking model and the direct solution model. While both enhancements significantly improve the backtracking models’ performance, the direct solution model still maintains a competitive edge, especially at higher test-time compute budgets.

Reinforcement Learning Changes Everything
When we apply Group Relative Policy Optimization (GRPO) to both backtracking and direct solution models, the additional fine-tuning dramatically changes their performance. Backtracking models, when fine-tuned with GRPO, don’t just improve—they soar beyond expectations. Remarkably, the post-GRPO backtracking model achieves nearly 70% accuracy at maximum test-time compute, significantly outperforming the original DFS-based solutions, which solve only 57% of the problems. Further analysis reveals that this performance boost stems from the model’s ability to discover novel search strategies—strategies not present in the supervised training data. This finding is especially compelling, as it demonstrates that reinforcement learning, when paired with backtracking capabilities, enables models to go beyond imitation and uncover more efficient reasoning paths.
In contrast, reinforcement learning has a markedly different effect on direct solution models. While these models become exceptionally strong at single-shot accuracy—achieving 42% at pass@1—they lose much of their capacity to generate diverse solutions. As a result, despite strong initial gains, their performance plateaus at higher test-time compute budgets. This reveals a clear trade-off: RL enhances immediate (pass@1) accuracy but undermines scalability and diversity in problem-solving, as measured by Best-of-N.

Conclusion
Backtracking is often thought of as a hallmark of intelligent reasoning—an ability to reflect, revise, and recover from errors. But our work shows that it’s not a silver bullet. In fact, whether or not backtracking helps depends crucially on the task structure, training data, and training paradigm.
Through controlled experiments on CountDown and Sudoku, we show that backtracking can either hinder or help, depending on whether sequential reasoning is actually needed. And when paired with reinforcement learning, backtracking truly shines—unlocking novel strategies that go beyond imitation. In contrast, models trained to generate final answers directly can be faster and more efficient, but at the cost of flexibility and diversity.
The bigger lesson is this: how we teach models to search—and whether they search at all—deeply shapes their reasoning behavior. As we build LLMs capable of more complex problem-solving, we need to move beyond one-size-fits-all solutions and toward more adaptive, task-aware reasoning strategies. Backtracking isn’t always the answer. But knowing when to backtrack—and when not to—might just be the key to smarter, more efficient models.
For more about our setup, methods, and findings, check out our paper!