
This blog is adapted from
Repeat After Me: Transformers are Better Than State Space Models at Copying
Repeat After Me: Transformers are Better than State Space Models at Copying
February 05, 2024Transformers are the workhorse of modern sequence modeling, achieving remarkable performance on a variety of tasks, but they have unavoidable inefficiencies. Specifically, the memory and compute used for generating every output token grows linearly with the input length. This means that generating n tokens requires O(n^2) compute, making training with long sequence lengths practically impossible.
Recently, State Space Models (SSMs) have emerged as a challenger to the Transformer architecture. These models can be interpreted as a type of recurrent neural networks (RNNs), which use a fixed-size memory that does not grow with the sequence length. This makes training and inference on long sequences much more efficient, opening up the possibility of feeding extremely long inputs, such as entire libraries, audio samples or DNA sequences, directly into the model.
Mamba, which is the leading SSM architecture, has demonstrated very impressive performance in language modeling. Remarkably, the paper that introduced the Mamba model demonstrated that it achieves better performance than competing Transformer models in many settings. Should we therefore abandon transformers in favor of a more efficient and better performing architecture?
In a new preprint, we (Samy Jelassi, David Brandfonbrener, Sham Kakade, Eran Malach) show that the improved efficiency of SSMs inevitably sacrifices some core capabilities that are crucial for modern language modeling. Specifically, we identify one particular capability that is sacrificed: the ability to retrieve and repeat parts of the input context. This task plays a key part in few-shot learning and retrieval which are two tasks that are ubiquitous in foundation models. Using theory and experiments, we show that Mamba models are inferior to Transformer-based language models on a variety of tasks that involve copying and retrieval. Importantly, we argue that this is not due to design flaws in the Mamba model, and in fact any model with fixed memory size will suffer from the same issues.
SSMs vs Transformers
Before introducing our results, we begin with a quick review of the memory considerations of Transformers, and how they compare to SSMs. Recall that the Transformer architecture takes a sequence of tokens as input and maps each token to a vector representation with some hidden dimension d. The model then alternates between token-level operations (represented with an MLP) and token-mixing operations (the attention layers). Therefore, for an input of length n, the output of each block is of size d x n. In particular, if we generate text auto-regressively token-by-token, then the size of the memory for storing the activations grows linearly with the numbers of generated tokens.
State-space models operate differently. Instead of performing operations over all previously observed tokens, SSMs effectively “compress” their inputs into a fixed-size latent state. This latent state is passed from one iteration to the next, but importantly does not grow in size when generating longer sequences. Therefore, SSMs are much more efficient when processing long inputs.

Representational capacity: Transformers copy exponentially longer strings than SSMs
In our theoretical results, we focus on a very simple task of copying the input text. I.e., we give the model an arbitrary sequence of tokens as input, and ask it to repeat the sequence verbatim. We prove two results. First, we show that a small Transformer can be used to copy extremely long sequences. Second, we show that any language model with fixed-size memory (i.e., any SSM) fails to copy long random strings.
Let us consider how a small Transformer can potentially copy very long input sequences. The idea is a generalization of the induction head mechanism, described by Olsson et al. (2022) as “a circuit whose function is to look back over the sequence for previous instances of the current token, find the token that came after it last time, and then predict that the same completion will occur again”. More generally, we show that Transformers can look back for occurrences of patterns of n tokens (n-grams), and complete the pattern based on the token that appears after the same n-gram. By repeating this process, Transformers are able to correctly copy very long input sequences, each time matching a small pattern in order to find the next token.
SSMs, on the other hand, have a fixed-size memory, so intuitively cannot store (and copy) inputs that are too long to fit in their memory. If the model doesn’t have enough capacity to store the input, then copying will likely contain errors.
These two observations demonstrate the theoretical gap between Transformers and SSMs: while the former can easily copy very long input sequences, the latter struggle to copy any sequence that does not fit in their memory.
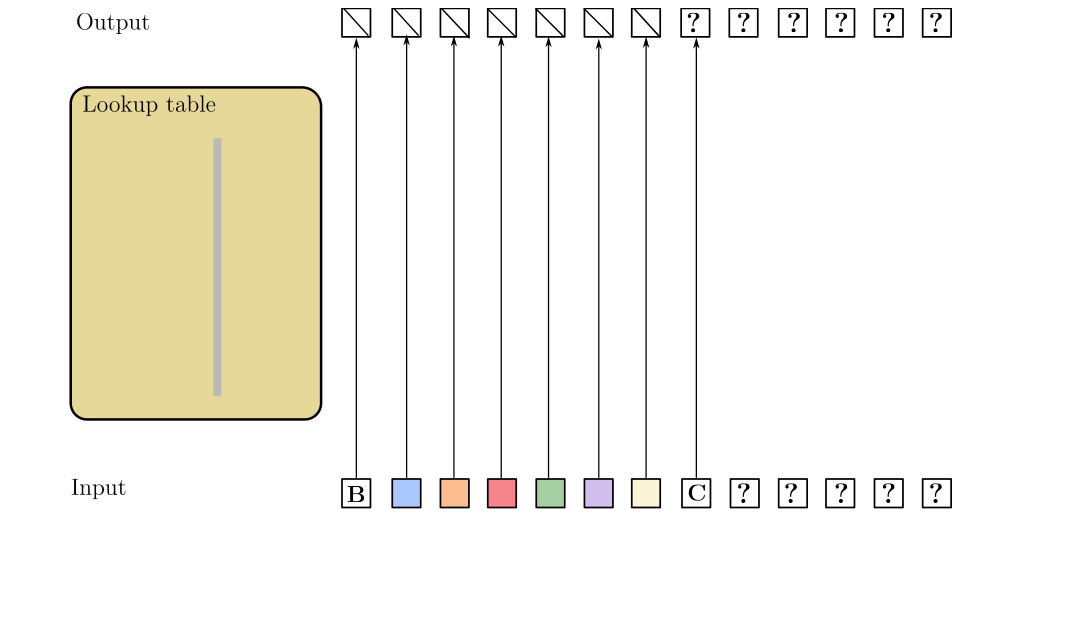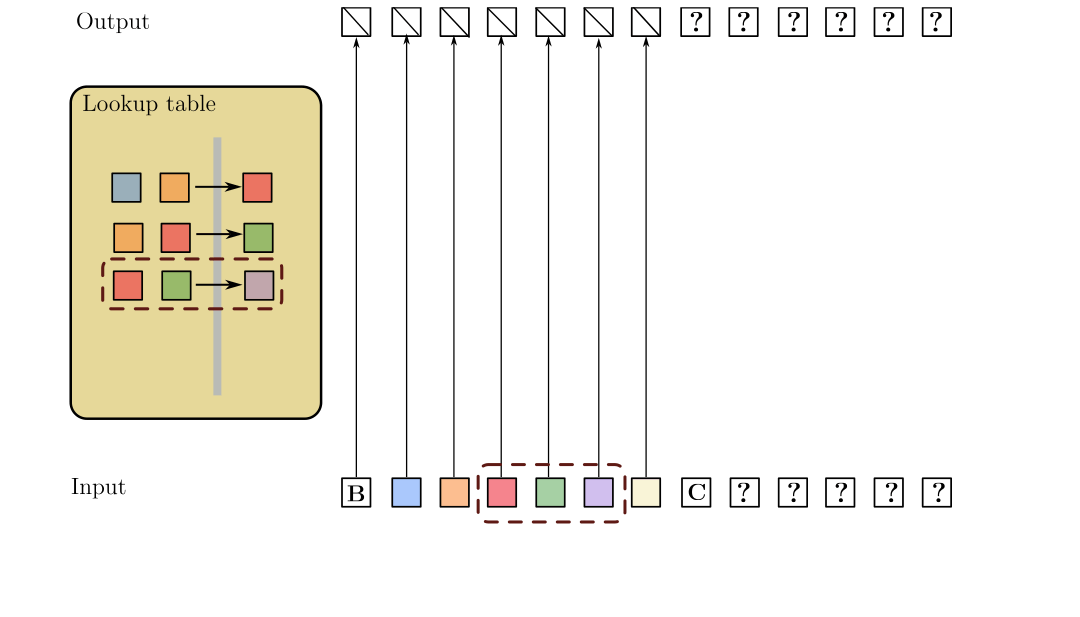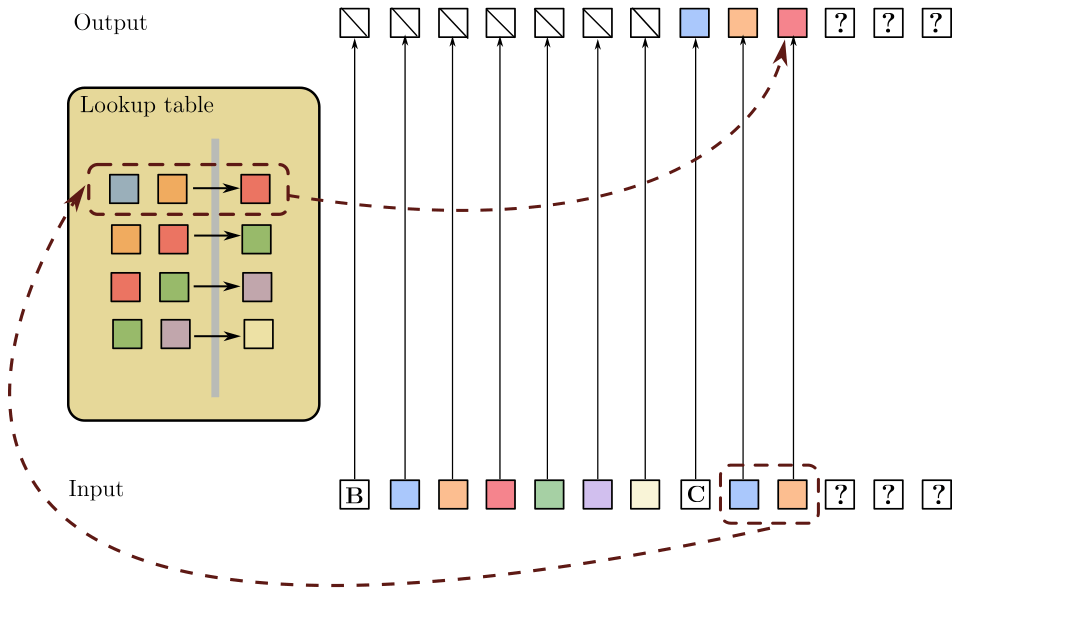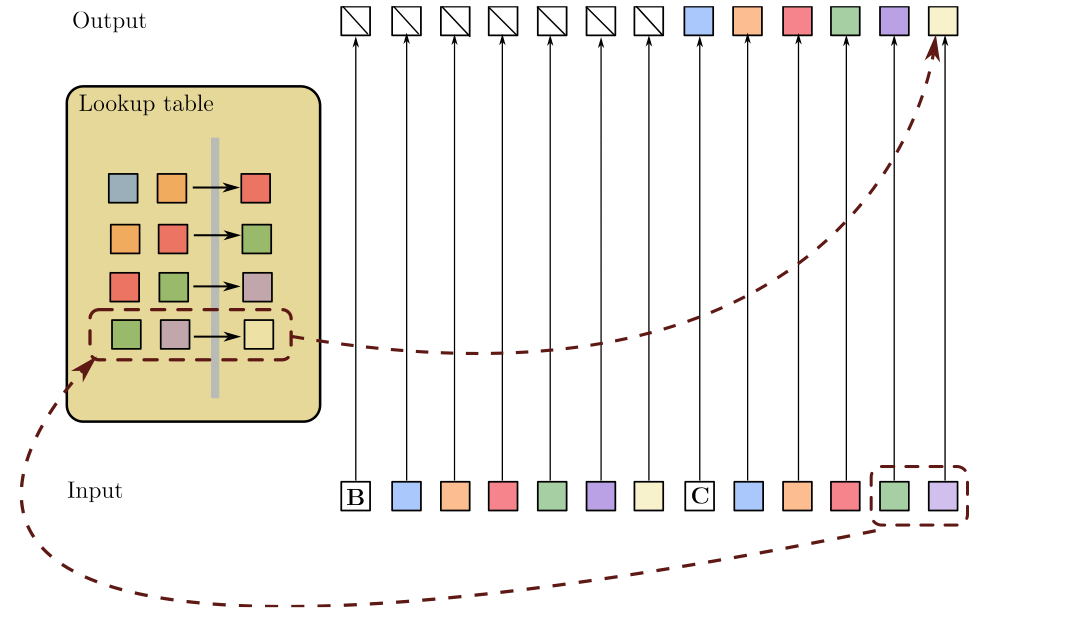
SSMs require 100x more data to learn copying long strings
We showed that in theory, small Transformers can copy long inputs, while SSMs cannot. We now turn to training actual models on the copy task, testing their ability to perfectly copy their input. That is, we randomly sample a sequence of up to 300 letters, and train Transformer and SSM-based causal language models to repeat the sequence. We observe that a small Transformer quickly learns to perfectly repeat the input string, while a Mamba model of a similar size fails. Even when we increase the size of the hidden state of the Mamba model so that it can store the input sequence, Mamba takes much longer to train, requiring 100x more data to learn copying compared to a Transformer based model.

Length generalization on the copy task
We find that Transformer models are also much better than SSMs at generalizing to inputs that are longer than the ones seen during training on the copy task. We compare Transformers and SSMs trained to copy strings of length < 50, and show that while SSMs fail to copy long strings that were not present during training, Transformers can accurately copy strings of length 100 and more. When we equip the Transformer with an improved positional embedding (Hard-ALiBi) motivated by our theoretical results (see more details in the paper), we observe that it maintains accurate performance when copying strings up to length 1000!

Pre-trained transformers with 10x less parameters outperform pre-trained SSMs
We now turn to study Transformer and Mamba-based models that are pre-trained on natural language datasets. Specifically, we compare a suite of Mamba and Pythia (Transformer-based, Biderman et al. (2023)) models, both of which are trained on The Pile (Gao et al. (2020)). We compare models of varying parameter count on a variety of tasks that involve copying and retrieval from the input context. We find that overall, pre-trained Transformers can outperform Mamba models with 10x more parameters on tasks that require information retrieval.
Phonebook retrieval: We test the ability of the pre-trained models to perform retrieval from the input context by presenting each model with a “phonebook”, asking it to retrieve the phone number of a particular individual. Namely, the model gets a list of random phonebook entries: “John Powel: 609-323-7777”, and is then asked for the phone number of a random person from the phonebook. Below we show that Transformer-based models perform this task much better than Mamba models of much larger size.

Copying natural language: In this experiment, we provide the models with chunks of text sampled from the C4 dataset, a large corpus of natural language data. We provide the models with two repetitions of the same text chunk, followed by the first word from the text, and expect it to generate an additional copy of the input text. We report string-level accuracy, measuring the probability of perfectly copying the input string. Indeed, we observe that Transformer based models reliably copy their input text, and that the accuracy of larger models remains high even for longer inputs. Mamba models, however, quickly degrade in performance when asked to copy long strings.

Question answering with long context: In our final experiment, we compare the 2.8B-parameter Mamba and Transformer models on the SQuAD question-answering dataset. This dataset provides text paragraphs of varying lengths together with a few questions regarding the text. We test both the Mamba and Transformer model on questions from this dataset, plotting the F1 score of their answers as a function of the paragraph length. We observe that while for short paragraphs, both the Pythia Transformer and Mamba achieve comparable performance, the performance of Mamba degrades with the paragraph length, while the transformer-based model maintains a similar accuracy even for longer texts.

Conclusions and Discussion
Our paper demonstrates, through theory and experiments, that Transformers are better than state space models at copying from their input context. However, we emphasize that SSMs have many advantages over Transformers. The memory and computational complexity of SSMs does not increase with the input length, which is ideal for training and inference on long inputs. Additionally, state space models such as RNNs are better at tracking state variables across long sequences, which may be useful for generating long consistent text. Importantly, language processing in the human brain appears to be much more similar to how state space models process language. We therefore believe that future work should focus on building hybrid architectures that endow state space models with an attention-like mechanism, allowing them to retrieve relevant pieces of text from their input. Indeed, humans have an incredibly limited capacity for memorizing sequences, but can translate entire novels if we allow them to look back at the text.