
This blog is adapted from
Mixture of Parrots: Experts improve memorization more than reasoning
Mixture of Parrots 🦜🦜🦜: Experts Improve Memorization More Than Reasoning
October 28, 2024Mixture-of-Experts (MoEs) are the backbone of many frontier models (GPT-4, Gemini, DBRX, Mixtral, Deepseek, Qwen2) that have achieved remarkable performance on a variety of tasks. They replace the single MLP in each Transformer block with multiple MLPs (called experts) and a router assigns each token to a few experts. As such, the number of “total” parameters in the models increases with the number of experts while the number of “active” parameters, i.e. the number of parameters that are actually used when generating each token, remains approximately constant. Therefore, MoEs offer an appealing way to increase scale while making training and inference relatively cheap.
This sets the following question: do MoEs offer a “free-lunch”, enabling gains in performance with no computational cost? Prior work (Fedus et al. 2022a, Fedus et al. 2022b) argues that when the number of total parameters is equal, MoEs “will always look worse” than Transformers.
In a new preprint, we (Samy Jelassi, Clara Mohri, David Brandfonbrener, Alex Gu, Nikhil Vyas, Nikhil Anand, David Alvarez-Melis, Yuanzhi Li, Sham Kakade, Eran Malach) show that the benefit from MoEs greatly depends on the task at hand. For reasoning-based tasks, MoEs indeed offer limited performance gains, and increasing the number of experts cannot compete with scaling the dimension (width) of the model. Surprisingly, for memory-intensive tasks, we show that scaling the number of experts is competitive with scaling standard “dense”’ MLPs, implying that for such tasks MoEs enable scaling the number parameters with minimal computational overhead. Taken together, our findings highlight that while MoEs can improve performance in certain cases, sometimes increasing the effective size (width) of the model is unavoidable.
Transformers vs MoEs
Before introducing our results, we begin with a quick review of the parameter count of Transformers, and how they compare to MoEs. Recall that the Transformer architecture takes a sequence of tokens as input and maps each token to a vector representation with some hidden dimension d. The model alternates between token-mixing operations (attention layers) and token-level operations represented by the Feed-Forward Networks (FFN). An estimate of the total number of parameters in these models is $O(L \cdot d^2)$, where L is the number of layers in the model and d is the width, and the attention and the FFN layer each consume $O(d^2)$ parameters. For Transformers, all the parameters are used when generating each token, so the number of active parameters (colored in red in the diagram) is equal to the number of total parameters.
MoEs operate differently. They replace the FFN layer in Transformers by a router module and multiple FFN layers, called experts. Then, the MoE’s router decides which experts process each token and eventually, the output is a weighted average of the outputs of these selected FFN layers. As such, the number of total parameters is $O(L \cdot E \cdot d^2)$, where E is the total number of experts, but the number of active parameters (colored in red in the diagram) is only $O(L \cdot K \cdot d^2)$, where K the number of selected experts. When K is close to 1, MoEs offer a “free-lunch” in that increasing the number of experts will only increase the number of total parameters (and not the number of active parameters) and thus, there is no computational overhead to run MoEs compared to dense Transformers.
For an equal number of active parameters, MoEs are strictly more expressive, so we could hope that for fixed compute budget MoEs are always at least as good as dense Transformers. For an equal number of total parameters, prior works (Fedus et al. 2022a, Fedus et al. 2022b) report that Transformers outperform MoEs. In the next sections, we show by experiments and theory that this actually depends on the task.
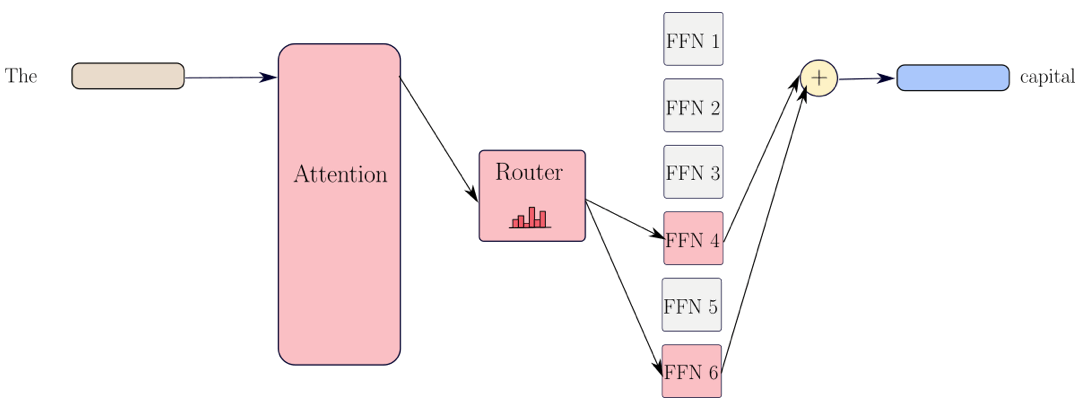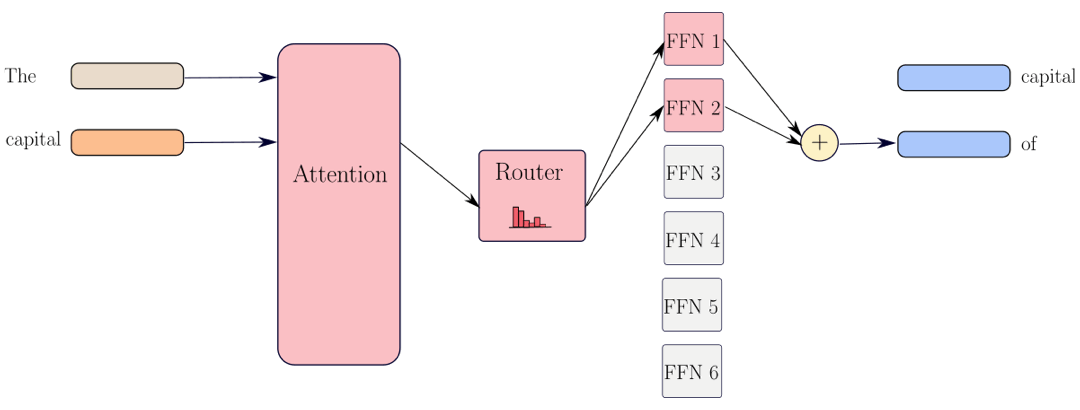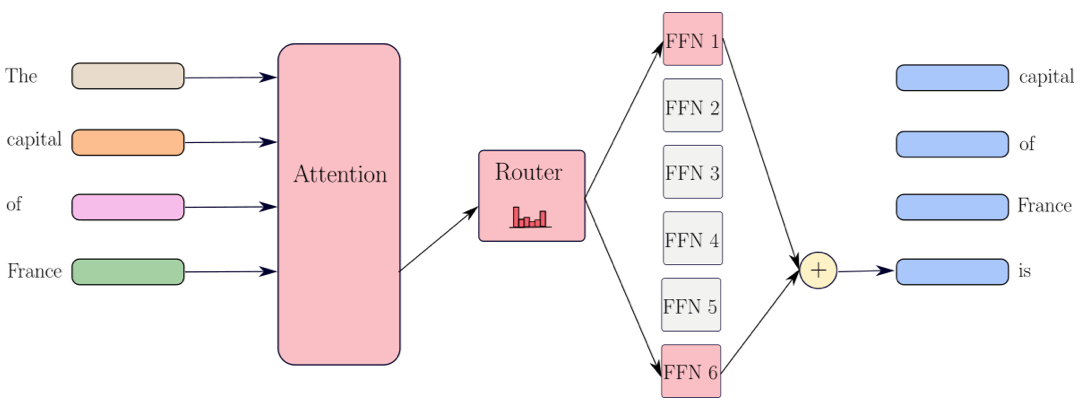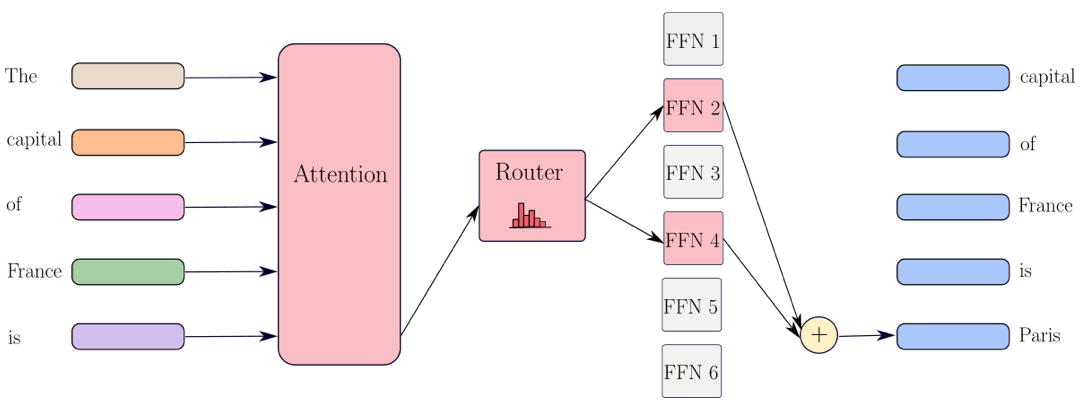
Representational capacity
We begin by a theoretical analysis of problems from two categories: reasoning-based and memorization-based problems, comparing MoEs and dense Transformers when fixing the number of active or total parameters. In all our results we focus on models with a single Transformer block (i.e. one attention layer and one FFN/MoE layer).
Reasoning on Graph Problem
We study a very simple graph problem: given an encoding of a graph with $n$ edges, the model needs to determine whether there exists a path of length 2 between two nodes. This is a simplified version of the shortest-path problem that we study empirically later. We begin by showing that, in order to solve the length-2-path problem, both dense Transformer and MoEs must have width that grows with $n$, the size of the graph. This result relies on communication-complexity lower bounds, using similar techniques to Sanford et al. 2024. Complementing this, we show a positive result, demonstrating that dense Transformers of width $O(n)$ can solve the length-2-path problem. Taken together, these results prove that, for certain reasoning-based problems, dense Transformers are better than MoEs when fixing the number of total parameters. Alternatively, fixing the number of active parameters, MoEs consume more memory but offer no benefit over dense Transformers.
Memorization
We shift to studying problems that require pure memorization. Specifically, the model is trained on $n$ random inputs with arbitrary next-token labels. In this case, we show that MoEs are much more powerful: an MoE with $\tilde{O}(n)$ number of total parameters can solve this task perfectly. Complementing this result, we show that any model requires at least $\Omega(n)$ parameters to solve this problem, demonstrating that when fixing the number of active parameters, MoEs significantly outperform dense Transformers.
For some reasoning problems, a critical width is needed
We showed that in theory, some reasoning problems can only be solved by models with a width beyond a critical dimension. We now turn to training actual models on the task of finding the shortest path in a graph. That is, we randomly sample graphs with 50 nodes and some fixed probability of assigning an edge, and train dense Transformer and MoE-based causal language models to find the shortest path (see figure above). We observe that when increasing their widths, Transformers substantially improve their performance. At a fixed width, adding more experts to MoEs yields limited performance gains. Therefore, when fixing the number of total parameters, Transformers outperform MoEs and the hidden size of the model is key for solving such reasoning tasks.
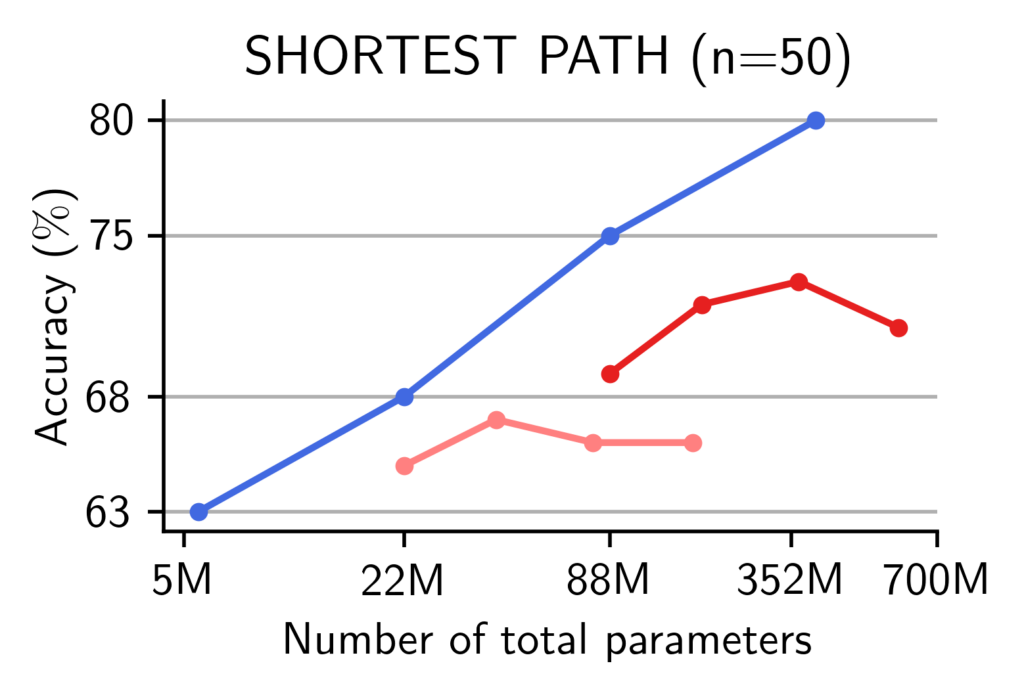
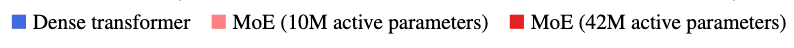
For memorization tasks, MoEs are better than dense Transformers
Surprisingly, we find that for a fixed number of total parameters, MoEs compete with Transformers on memory intensive tasks, such as closed-book lookup tasks. We randomly sample phone-books of different sizes and train Transformers and MoEs to memorize them. At inference time, we ask the model to retrieve the phone number of a particular individual. Namely, the model is trained on a list of random phonebook entries “John Powell 609-323-7777’ and is then asked for the phone number of a random person from the phonebook. We report the size of the largest phone-book where the model succeeded in 90% of the queries. No matter the number of active parameters, MoEs match the performance of dense Transformers with the same number of total parameters. This suggests that MoEs are able to effectively leverage the extra parameters in additional experts by routing tokens to the experts that contain the necessary information from the training corpus.
This scaling is remarkable in this case since it even holds when we are only routing to 2 out of 64 experts. For instance, we find that an MoE model with only 42M active parameters outperforms a dense model with 10x as many parameters.
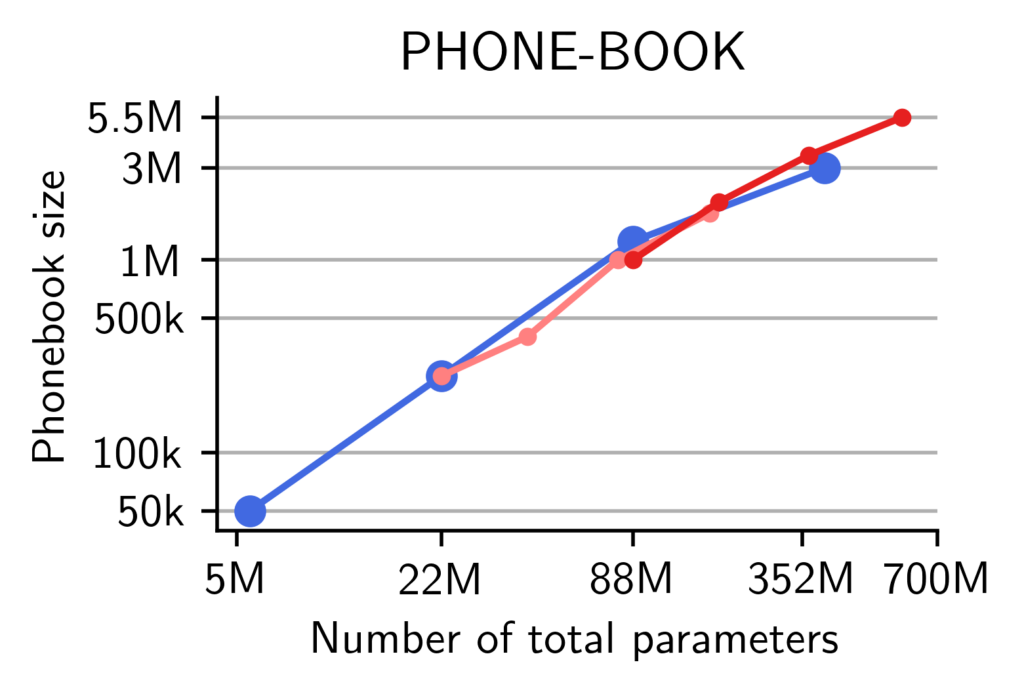
Comparing pre-trained MoEs and dense Transformers on downstream tasks
We now turn to study Transformers and MoEs that are pre-trained on natural language datasets. Specifically, we train two collections of models, one series on natural language and another one on math. We compare models of varying widths and number of experts and compare their performance on the following commonsense, world-knowledge and math benchmarks:
- World Knowledge: TriviaQA, Natural Questions, HotpotQA, WebQuestions, Complex WebQuestions
- Commonsense: ARC datasets, CommonsenseQA, HellaSwag, OpenbookQA, PIQA, SciQ, SIQA,, WinoGrande
- Math: GSM8k, GSM-Hard, Hendrycks-MATH, Minerva-MATH, SVAMP
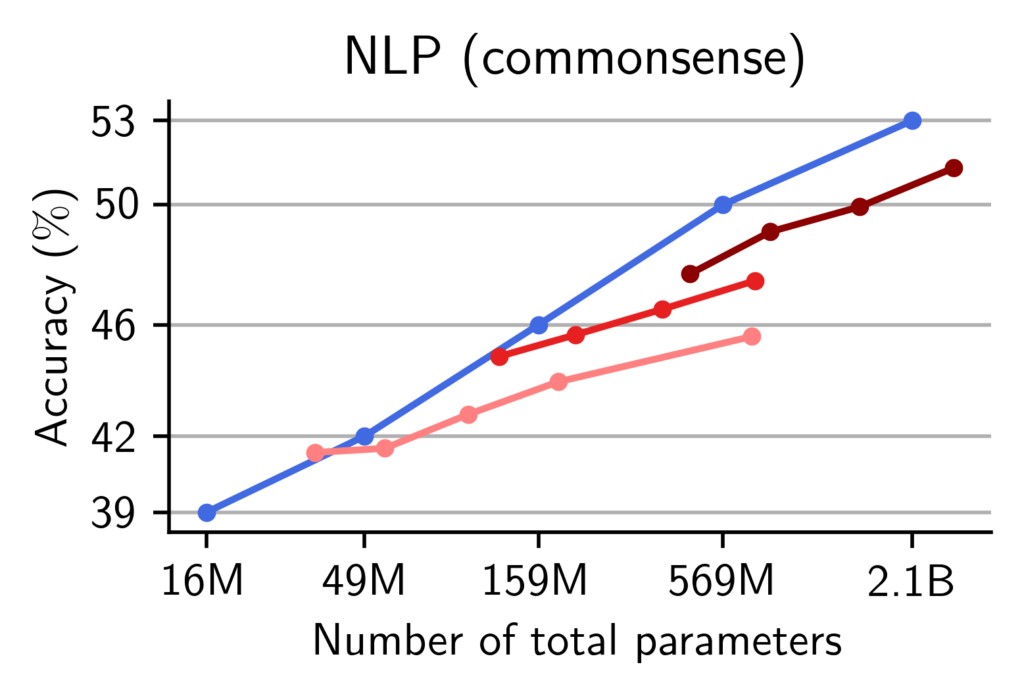
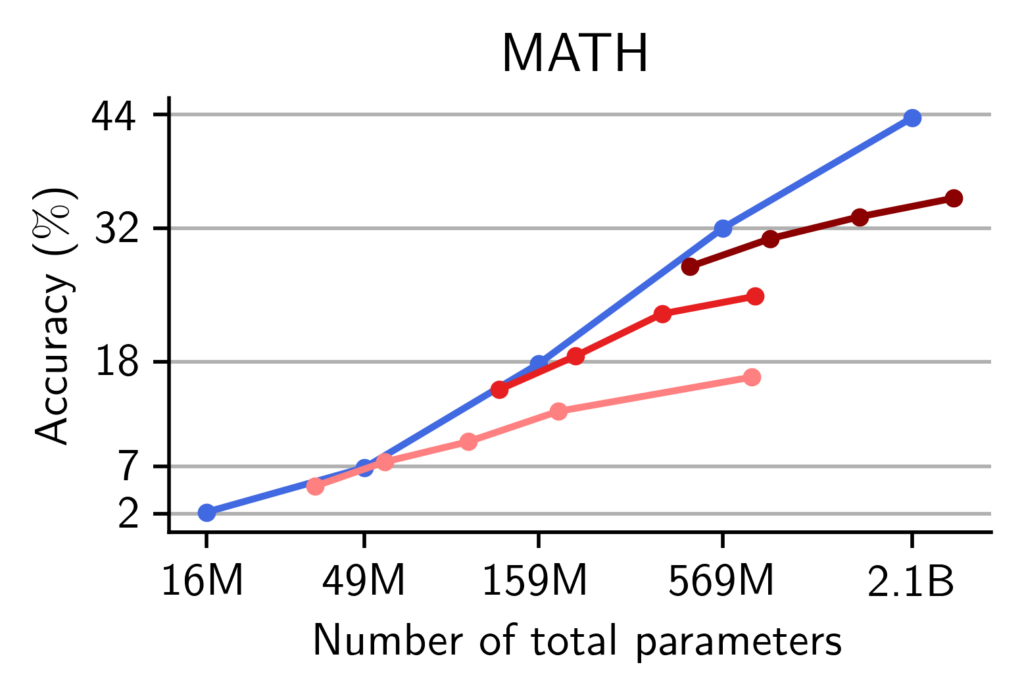
We report the averaged accuracy across each of these categories. We find that for a fixed number of total parameters, pre-trained MoEs match the performance of pre-trained Transformers on world-knowledge tasks, no matter the width of the models. On commonsense and reasoning tasks, however, the models need a critical width to well-perform.
Experts improve memorization more than reasoning. We observe that our theory and the synthetic experiments also hold when pre-training and evaluating language models on natural language and math. We report the accuracy of our models with respect to the number of total parameters. On world-knowledge tasks, we find that regardless of the number of active parameters, MoEs can effectively use their routing to leverage all of their parameters to solve memory-intensive tasks. On the other hand, on commonsense and math benchmarks, MoEs do not reach the performance of dense models with the same number of total parameters.
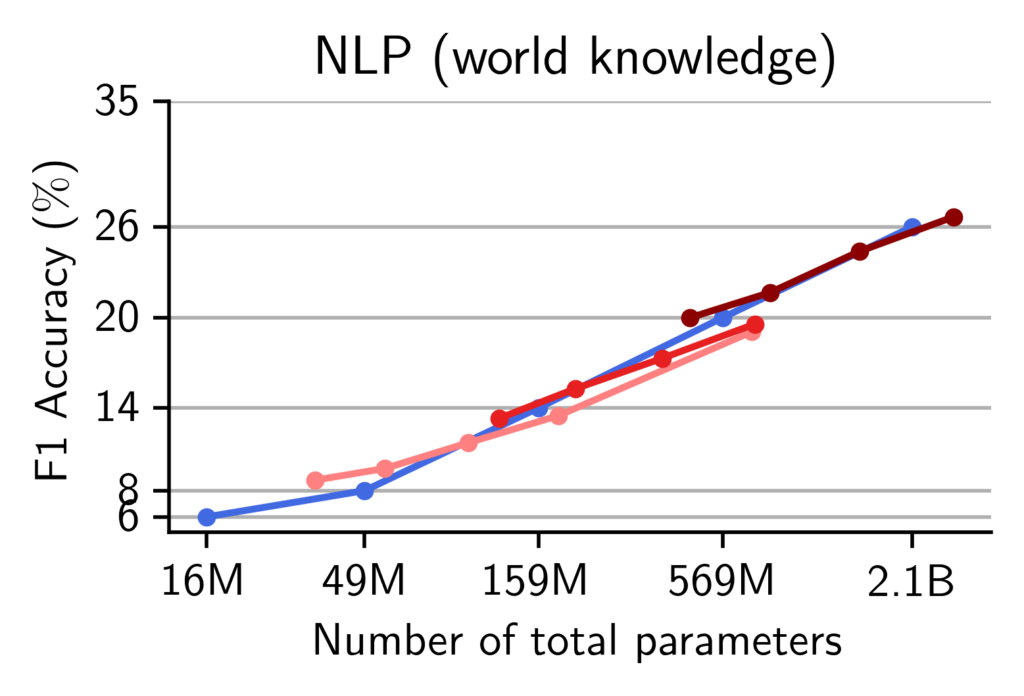

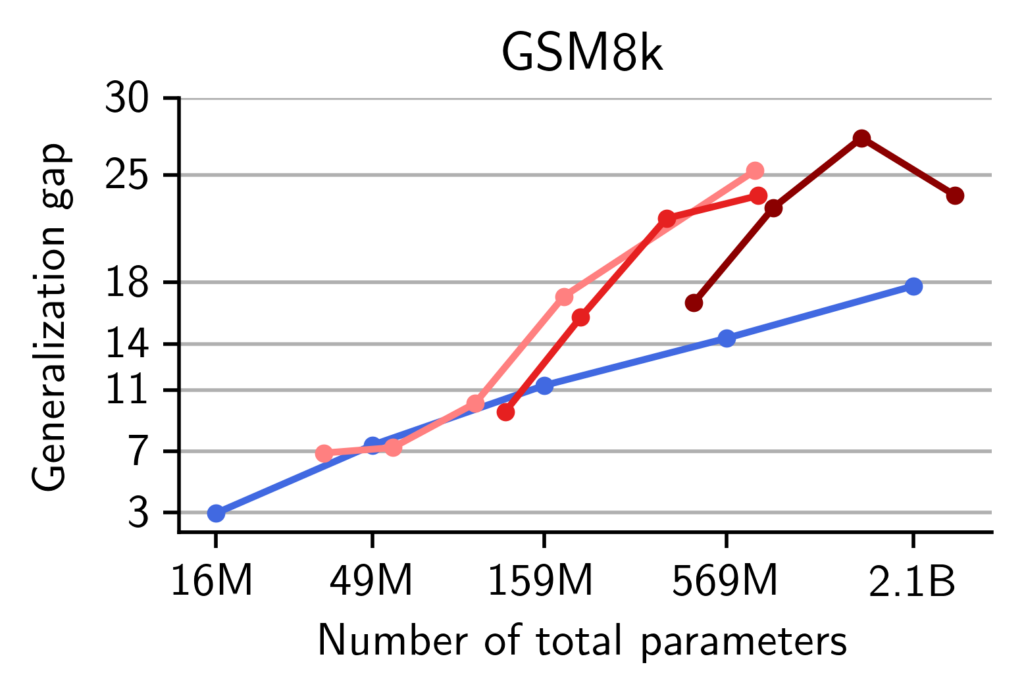
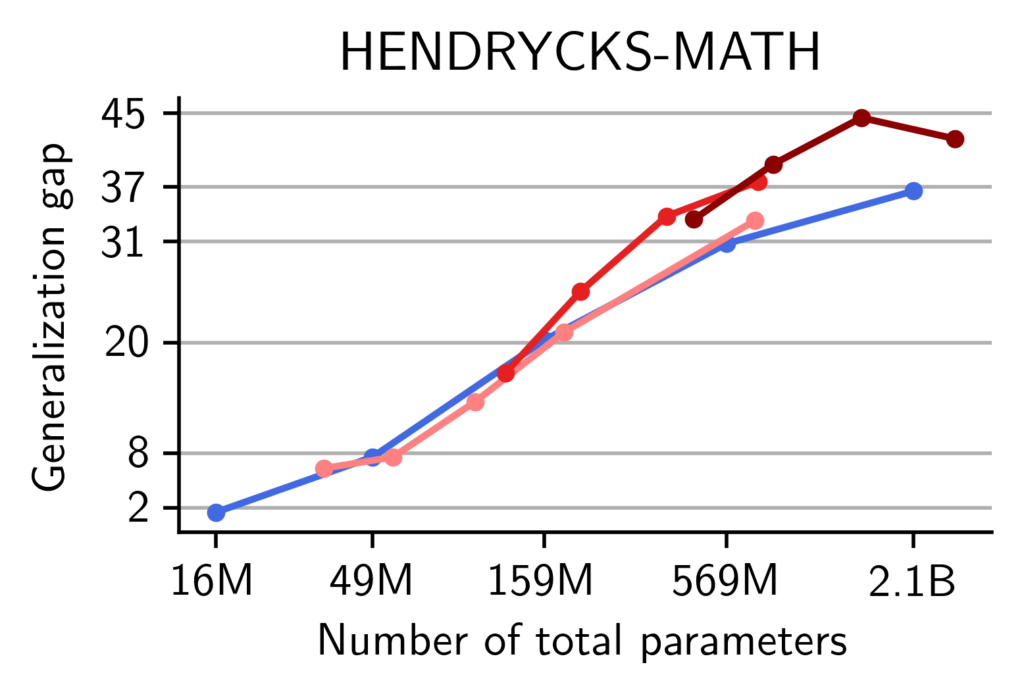
On math, MoEs display a higher train-test gap than dense models, suggestive of memorization. We provide additional evidence that memorization occurs in pre-trained MoEs. Our models are pre-trained on the OpenMathInstruct dataset (Toshniwal et al., 2024) (among other data sources). This is a math instruction tuning dataset with 1.8 million problem-solution pairs. The problems are taken from the GSM8k and Hendrycks-MATH training subsets and the solutions synthetically generated using Mixtral-8x7b. Therefore, to quantify the memorization of our models, we measure the generalization gap i.e. the difference in accuracy, between a model evaluated on the training problems and the same model evaluated on the test sets of GSM8k and Hendrycks-MATH.
While both Transformers and MoEs make a single pass on OpenMathInstruct, we observe that at scales beyond 159M parameters, MoEs suffer from a more significant generalization gap than dense Transformers. This is suggestive that MoEs are more prone to memorizing training data compared to dense models.
Conclusion and discussion
Our paper demonstrates, through theory and experiments, that in MoEs, experts improve memorization more than reasoning. Overall, the performance on memory intensive tasks seems to be correlated with the total number of parameters while on reasoning tasks, the width of the model seems to be key. Taken together, our work suggests that while MoEs are valuable as memorization machines, additional architectural innovations are needed to reduce the computational load for reasoning-intensive tasks.
Acknowledgements
All this work has only been possible thanks to the Kempner Institute computing resources and the support from their Research & Engineering team. SJ particularly thanks Max Shad for his support during the project.