
This blog is adapted from
Large Video Planner Enables Generalizable Robot Control
Large Video Planner: A New Foundation Model for General-Purpose Robots
January 05, 2026Recent progress in AI has been driven by foundation models trained on internet-scale data. This has inspired a new wave of “robot foundation models” aimed at solving generalization, but such models rely on the text information of large language models, which do not capture the details dynamics of the physical world. This work explores an alternative paradigm: using video as the primary modality for robot foundation models. Unlike static images, videos naturally encode physical dynamics and semantics of the world, providing a rich prior for physical decision-making.
The grand challenge of modern robotics is generalization. For decades, we have excelled at building robots for specific, repetitive tasks in controlled settings like factory floors. But the dream of a general-purpose robot—one that can operate safely and effectively in the messy, unpredictable “in-the-wild” environments of our homes, offices, and hospitals—remains a central challenge.
Recent progress in AI has been driven by foundation models trained on internet-scale data. This has inspired a new wave of “robot foundation models” aimed at solving generalization. The most common approach is the Vision-Language-Action (VLA) model, which extends large multimodal models (MLLMs) to output robot actions. VLA models are built on the intuition that MLLMs, pre-trained on web-scale text and images, can transfer their rich perceptual and linguistic understanding to the new modality of robot actions. But there’s a catch: robot action data is orders of magnitude scarcer than text and image data.
This creates an “asymmetric transfer” problem. An MLLM may learn to recognize a “cup” from billions of images, but it must learn to grasp that cup from a comparatively tiny dataset of robot-specific trajectories. This scarcity makes it incredibly difficult for models to generalize to novel tasks and objects they haven’t been explicitly trained on. As a result, VLAs often depend on this asymmetric transfer, where the action-mapping itself must be learned from limited data.
What if we could find a data source for action that is as abundant as the data for vision and language?
Our Approach: Video as a Visual Planner
In our work, we explore an alternative paradigm: using video as the primary modality for robot foundation models.
Unlike static images, videos naturally encode temporally and spatially extended state-action trajectories. They visually depict how the world evolves as agents interact with it. A video of a person opening a door is a rich, continuous, and physically coherent representation of an action plan.
Crucially, video data is abundant. The internet is filled with human activities, instructional tutorials, and task demonstrations. This data implicitly contains action information, offering a directly grounded source of transfer that provides a stronger bridge to embodied tasks than the asymmetric transfer of VLAs.
Our approach reframes the problem. Instead of asking the model to map (Image + Instruction) → (Robot Action), we ask it to generate a visual action plan. Given a starting image and a text prompt like “Please pull a piece of tape,” our model generates a video showing how the task should be completed. This video plan is then translated into executable robot actions.
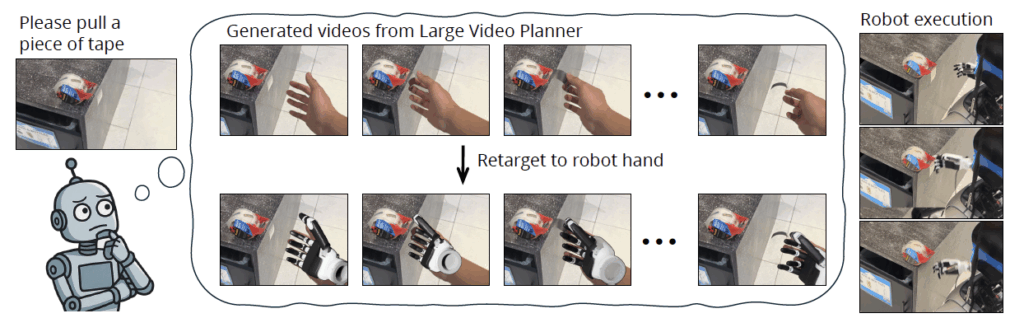
Building the Large Video Planner
To realize this vision, we made contributions in both data and model design.
1. The LVP-1M Dataset: Standard video datasets are often optimized for content creation, not for learning physical interactions. We curated and released LVP-1M, a large-scale, open dataset of 1.4 million video clips specifically tailored for embodied decision-making. It combines the rich diversity of human-centric videos from sources like Ego4D with the clean, task-focused demonstrations from robotics datasets like DROID. We carefully processed this data with action-focused captioning and temporal alignment to create a robust training source for action dynamics.
2. The Large Video Planning Model: We developed LVP, a large-scale video foundation model purpose-built for embodied reasoning and action extraction. It uses a latent diffusion transformer architecture modified with two key techniques:
- Diffusion Forcing: This allows the model to be jointly trained on both image-to-video and video-to-video tasks, enabling it to plan from a single frame or extend an existing video sequence.
- History Guidance: This novel sampling technique enhances temporal coherence, ensuring the generated video plan remains physically consistent and faithful to the initial observation frame.
3. The Video-to-Action Pipeline: A video plan is useless if the robot can’t execute it. We designed a modular pipeline to bridge this gap. First, our LVP model generates a plan depicting a human hand. We then use 3D reconstruction models (HaMeR and MegaSAM) to estimate the precise 3D trajectory of the hand and wrist in the video. Finally, this human motion is “retargeted” to the specific morphology of the robot, translating the visual plan into concrete, executable joint commands for either a simple parallel gripper or a complex, multi-fingered dexterous hand.
The Impact: Zero-Shot Generalization in the Wild
We focused our evaluation on true task-level generalization—performing novel tasks the model has never encountered, not just new configurations of trained tasks.
First, we crowdsourced a challenging test set of 100 novel prompts from third-party participants using their own everyday environments, with tasks like “pull out a tissue” and “open an outdoor gate”. In this in-the-wild evaluation, Kinesis’s video plans were far more coherent and physically plausible than strong baselines. Our model achieved a 59.3% success rate on “Task Complete” (Level 3), significantly outperforming the next-best model’s 39.3%.
Next, we deployed the full end-to-end pipeline on real robots. Our system demonstrated successful zero-shot execution on a Franka arm with a parallel gripper and, more impressively, on a G1 arm with a dexterous hand. It successfully performed complex, fine-grained tasks like “scooping coffee beans” and “tearing off clear tape”—tasks that were not in its training data. In these tests, our video-planner approach consistently outperformed state-of-the-art VLA baselines, which struggled to generalize to these out-of-distribution tasks.
The Future of Embodied AI
This work demonstrates that leveraging internet-scale video data for generative planning is a powerful and viable paradigm for building general-purpose robots. By training models to first visualize how to act, we can tap into a near-limitless source of human demonstration data.
To support this new direction, we are releasing both our LVP model and the LVP-1M dataset to the research community, supporting an open and reproducible future for video-based robot learning.