
This blog is adapted from
Matching Features, Not Tokens: Energy-Based Fine-Tuning of Language Models
Energy-Based Fine-Tuning: Beyond Next-Token Prediction
March 16, 2026Language models trained with teacher forcing never learn to handle errors that compound during generation. Reinforcement learning with verifiable rewards (RLVR) fixes this by training on rollouts, but only provides a scalar reward and hurts calibration. We introduce Energy-Based Fine-Tuning (EBFT), which matches the statistics of generated sequences to ground-truth completions in feature space. In our experiments, EBFT matches RLVR on accuracy without needing any reward or verifier, while also improving perplexity and the quality of the model’s output distribution. It works on any text data, scales consistently from 1.5B to 7B parameters, and generalizes better out-of-distribution.
The Compounding Error Problem
Language models are trained on ground-truth text but must generate from their own outputs. This mismatch is subtle during training — the model never conditions on its own predictions — but it compounds at inference time. An early error shifts the conditioning context, the next token is sampled from a distribution the model was rarely trained on, and the problem snowballs. The longer the generation, the worse it gets.
The standard training objective, next-token cross-entropy under teacher forcing,
$$\mathcal{L}_{\text{CE}} = -\mathbb{E}{(c,y)} \log p_\theta(y \mid c)$$
provides a dense, stable learning signal that scales efficiently. In principle, if optimized to zero, it recovers the true data distribution and the compounding problem disappears. But in practice, we are never in that regime. Every real model carries residual error, and teacher forcing provides no mechanism to correct for how that error propagates across multiple generation steps.
Braverman et al. (2019) made this concrete by measuring the conditional entropy of the $k$-th generated token as a function of $k$. For a perfectly calibrated model — one whose generations are distributionally indistinguishable from real text — this quantity should be flat. But they found it grows steadily, revealing that the model’s uncertainty compounds as it conditions on increasingly off-distribution text.
We observe the same phenomenon through a different lens. The figure below shows a feature-matching loss — measuring how well the statistics of model rollouts match those of ground-truth completions in a learned embedding space — as a function of completion length.
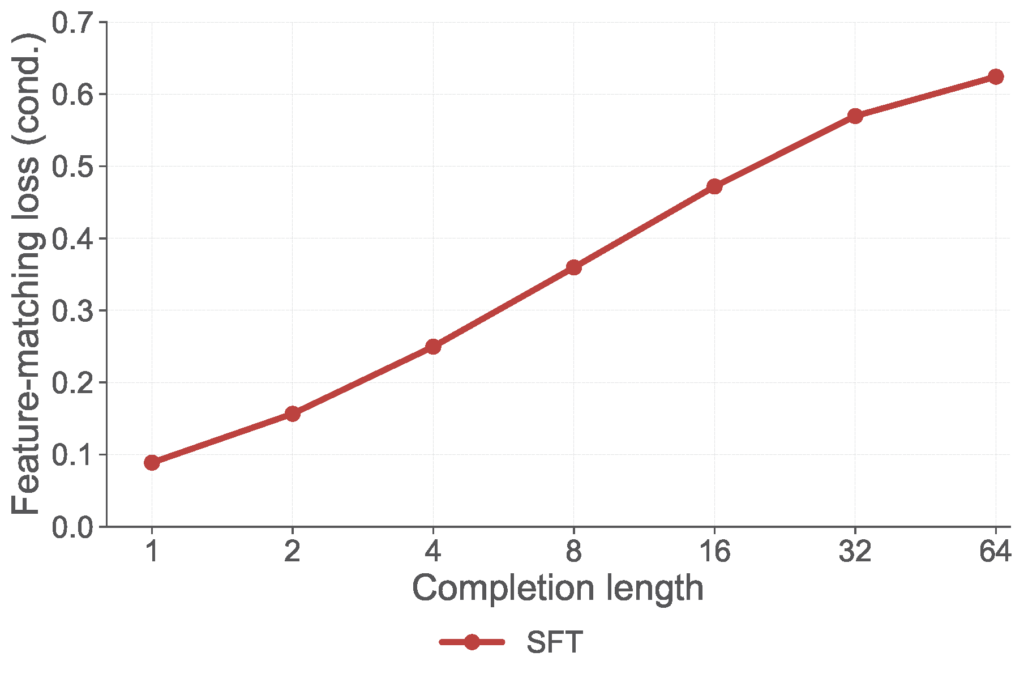
The steady increase reflects a genuine calibration failure: SFT does not account for how the model’s distribution drifts over its own generations. This is the gap we set out to close. Rather than treating this divergence as an inevitable byproduct of teacher forcing, we ask: can we define a training objective that directly targets these long-range statistics and optimize it.
Why Existing Solutions Fall Short
Two dominant fine-tuning paradigms exist, and each addresses only part of the problem.
Supervised fine-tuning (SFT) optimizes next-token cross-entropy under teacher forcing. It never evaluates the model on its own generations, so it cannot directly optimize the sequence-level statistics that matter at inference time.
Reinforcement learning with verifiable rewards (RLVR) is a natural fix: it operates on full rollouts and optimizes sequence-level correctness. But that signal is a single scalar reward which tells the model whether the code was correct, not how. In practice, RLVR can improve downstream accuracy while substantially degrading validation cross-entropy.
What’s missing is a training signal that is both sequence-level and distributional — one that asks not “is this output correct?” but “does the distribution of outputs match the distribution of real completions?”
| Trains on rollouts? | Sequence-level signal? | Preserves calibration? | |
|---|---|---|---|
| SFT | No, teacher forcing only | No, token-level loss | Yes |
| RLVR | Yes | Scalar reward only | No, CE often degrades |
| EBFT (ours) | Yes | Dense, feature-level | Yes, CE improves |
A New Objective: Matching Long-Range Statistics
We introduce a feature-matching loss that directly measures how well the model’s rollout distribution matches the ground-truth distribution in a learned embedding space:
$$\mathcal{L}_{\text{FM}} = \mathbb{E}_c \left\| \mathbb{E}_{\hat{y} \sim p_\theta(\cdot|c)}[\phi(c:\hat{y})] – \mathbb{E}_{y \sim p(\cdot|c)}[\phi(c:y)] \right\|^2$$
Here $\phi(c:y)$ is a feature embedding of the full prompt–completion sequence, constructed by extracting and concatenating intermediate activations from a frozen copy of the pretrained model. Instead of asking “did we predict the next token correctly?”, we ask: do the model’s generated sequences match the statistics of real completions in feature space?
Under a sufficiently rich feature map, $\mathcal{L}_{\text{FM}}$ is a strictly proper scoring rule — it can only be minimized by the true conditional distribution. Moreover, it shares the same minimizer as cross-entropy, so there is no inherent tension between the two objectives. In our experiments, optimizing $\mathcal{L}_{\text{FM}}$ improves both.
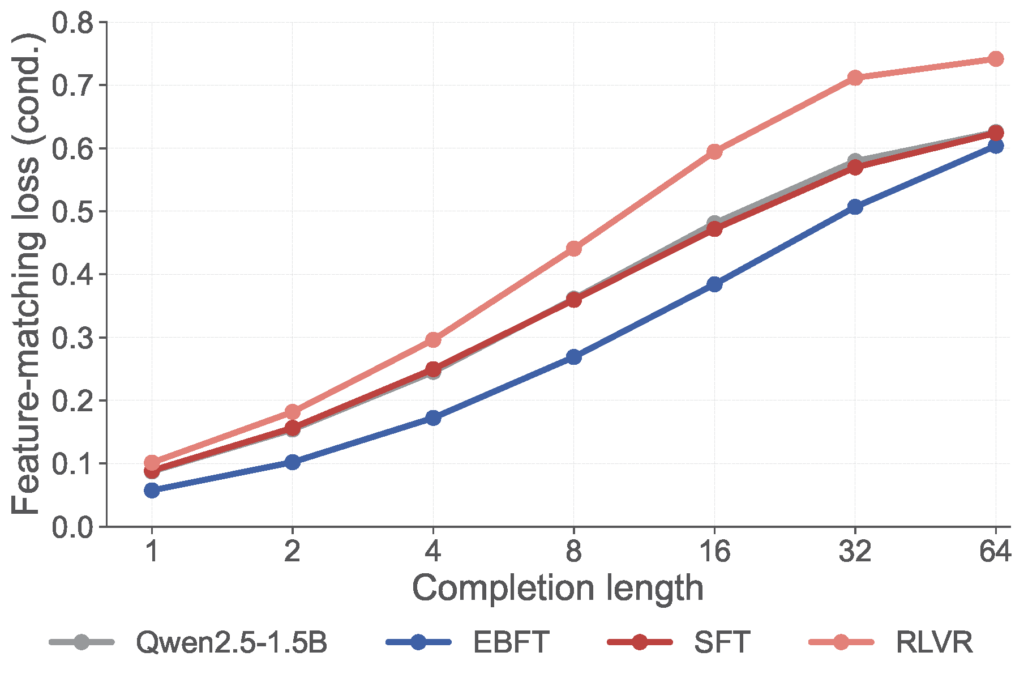
The figure below shows what happens when we actually optimize this loss. EBFT — our method for minimizing $\mathcal{L}_{\text{FM}}$, introduced in the next section — achieves the lowest feature-matching loss across all completion lengths, despite training with rollouts of only 8 tokens. RLVR, by contrast, worsens this loss relative to the base model.
Energy-Based Fine-Tuning (EBFT)
How do we minimize $\mathcal{L}_{\text{FM}}$ in practice? We can’t backpropagate through the sampling process, so we use a REINFORCE-style gradient estimator. For each prompt, the generator samples $n$ short completions on-policy — just 8 tokens in our experiments — and a frozen feature network embeds both the generated and ground-truth sequences. Each completion receives a reward that drives a policy gradient update.
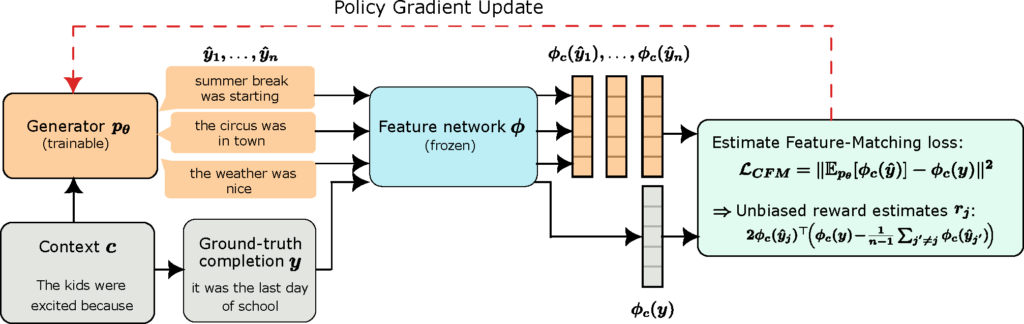
The reward for each generated completion decomposes into two intuitive terms:
$$r_j = \underbrace{2\, \phi_c(\hat{y}j)^\top \phi_c(y)}_{\text{alignment}} \;-\; \underbrace{\frac{2}{n-1} \sum_{j’ \neq j} \phi_c(\hat{y}j)^\top \phi_c(\hat{y}{j’})}_{\text{diversity}}$$
The alignment term rewards completions whose features are close to the ground truth — pushing the model toward semantically faithful outputs. The diversity term penalizes completions that are too similar to each other — preventing the model from collapsing onto a single mode. Together, they encourage the model to cover the ground-truth distribution rather than merely imitating one example.
In practice, we optimize a combined objective:
$$\mathcal{L}(\theta) = \mathcal{L}_{\text{FM}}(\theta) + \gamma\, \mathcal{L}_{\text{CE}}(\theta), \qquad \gamma > 0.$$
The feature-matching loss handles sequence-level calibration; the cross-entropy term provides the familiar token-level signal. Since both losses share the same minimizer — the true data distribution — they work together rather than against each other.
EBFT Improves Both Accuracy and Calibration
The usual story in LLM fine-tuning is one of tradeoffs: RLVR improves accuracy but hurts perplexity; SFT preserves perplexity but lags on downstream tasks. EBFT sidesteps this tradeoff entirely. The figure below tracks four metrics over training on Q&A coding (Qwen2.5-1.5B trained on OpenCodeInstruct):
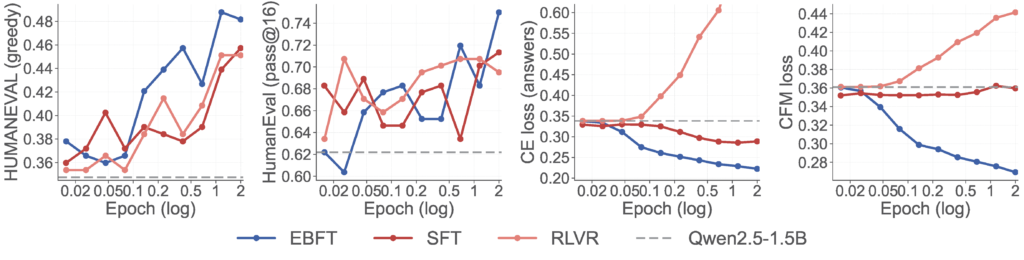
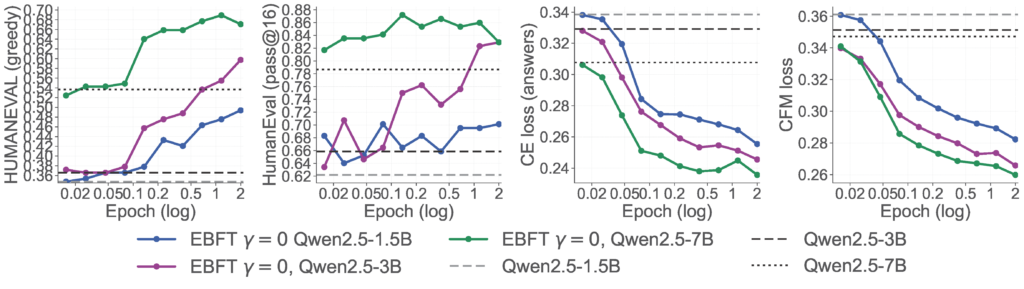
EBFT matches RLVR on accuracy — without any reward signal (left two panels). EBFT reaches the highest HumanEval scores on both greedy and pass@16, outperforming SFT and matching or exceeding RLVR — despite never seeing a single unit test.
EBFT beats SFT at cross-entropy — despite not optimizing it (third panel). EBFT drives CE below SFT, even though SFT directly optimizes this objective. Meanwhile, RLVR’s CE shoots up throughout training, far exceeding the base model — the model gets better at passing tests while becoming a worse language model.
RLVR degrades distributional quality; EBFT improves it (fourth panel). EBFT steadily improves the feature-matching loss; SFT is roughly flat; RLVR actively degrades it relative to the base model.
We evaluate across three settings: Q&A coding, where the model trains on programming prompts paired with reference solutions (OpenCodeInstruct); unstructured code, where it trains on raw Python from GitHub with no prompts or instructions (SwallowCode); and translation, where it trains on human-curated parallel sentence pairs (ALMA). On translation, the same ordering holds: EBFT achieves the best COMET scores on WMT22 and MTNT, while RLVR’s cross-entropy rises well above the base model.
Why This Matters in Practice
EBFT needs no verifier — it works on any text. RLVR requires a correctness signal: unit tests for code, exact-match answers for math. Most training data has none of this. On unstructured code — raw Python scraped from GitHub, with no test cases — RLVR is simply inapplicable, leaving SFT as the only option. EBFT breaks this limitation: it only needs ground-truth text, and it substantially outperforms SFT in this setting.
EBFT generalizes better out-of-distribution. On non-Python programming languages (MultiPL-E), SFT degrades performance relative to the base model — but EBFT improves it. On noisy user-generated translation (MTNT), EBFT outperforms both SFT and RLVR. Training on feature-matching appears to produce representations that transfer more robustly than those from token-level or reward-level objectives.
EBFT scales consistently across model sizes. We run EBFT on Qwen2.5 at 1.5B, 3B, and 7B parameters, each using a frozen copy of itself as the feature network. The improvements are consistent across all three scales, with no sign of diminishing returns.
Conclusion
Next-token cross-entropy trains models on ground-truth prefixes but never checks what happens when they generate on their own. RLVR checks — but only with a scalar reward, and at the cost of degrading distributional quality. EBFT offers a third path: match the statistics of model rollouts to those of real completions in feature space, improving downstream accuracy, cross-entropy, and calibration simultaneously, without requiring any task-specific reward or verifier.
This makes EBFT applicable to the vast majority of training data, e.g. raw code, unstructured text, where RLVR simply cannot be used. We view feature matching as a complementary training signal that bridges the gap between token-level likelihood and rollout-based optimization. More details are available in the paper.