
This blog is adapted from
Contrastive learning explains the emergence and function of visual category-selective regions
Contrastive Learning Explains the Emergence and Function of Visual Category Selectivity
September 25, 2024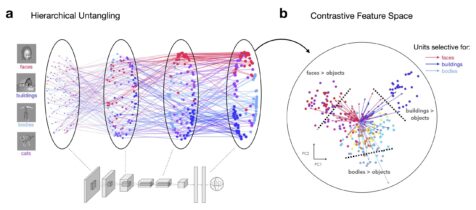
A low-dimensional projection of category-selective axes in a contrastive feature space. Self-supervised learning naturally untangles visual categories, yielding specialized representations without the need for hard-coded category-specific mechanisms
How does the visual system support our effortless ability to recognize faces, places, objects, and words?
Decades of fMRI studies have provided researchers with an important clue: the existence of category-selective regions in the ventral visual cortex that respond to these different inputs. However, the pressures guiding the emergence of these regions and their computational role in visual recognition remain intensely debated.
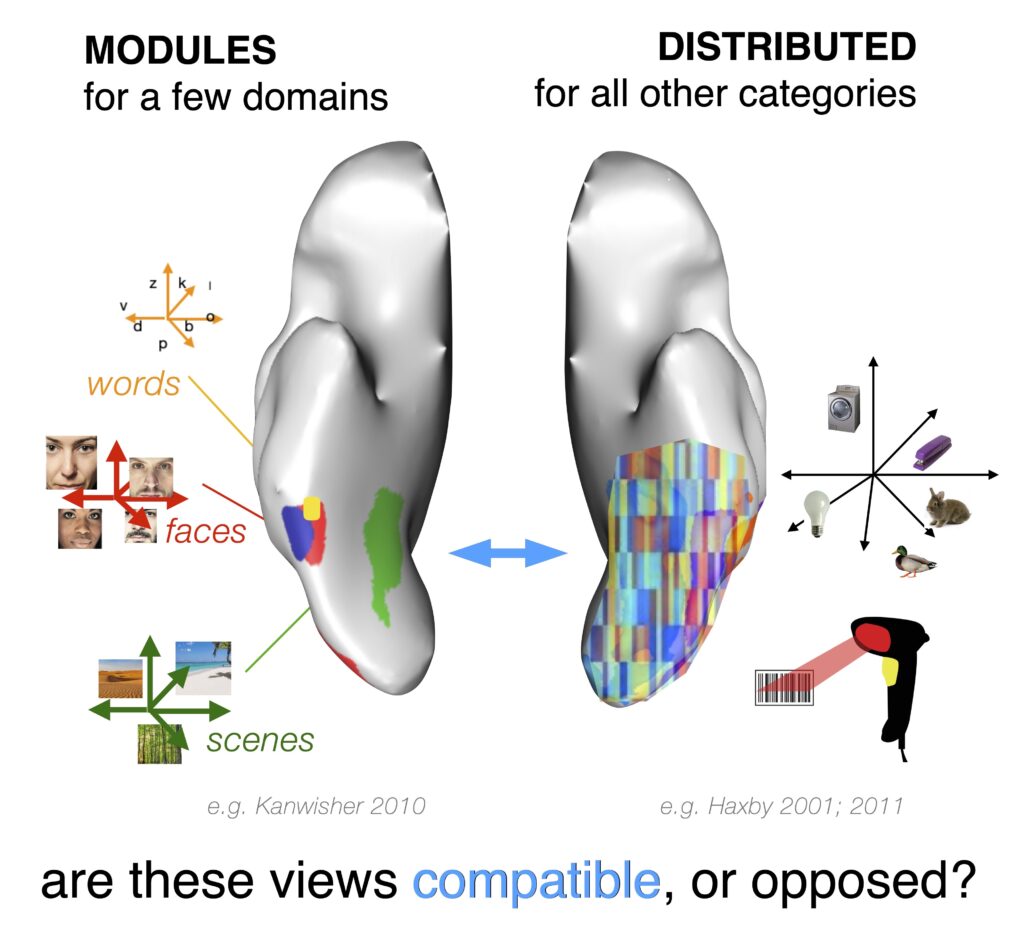
Classical theories suggest that category-selective regions function as dedicated modules, with discrete brain areas specializing in processing specific visual domains such as faces or places. An alternative set of distributed coding theories propose that category information is instead spread across large populations of neurons, forming a kind of “bar code” where the entire population—across all selective regions—works together to recognize objects.
In a new study, published in Science Advances, we introduce an updated framework for understanding visual object recognition and category selectivity: contrastive coding. Using AI models and large-scale visual neuroimaging data, we show how this approach bridges the gap between modular and distributed coding.
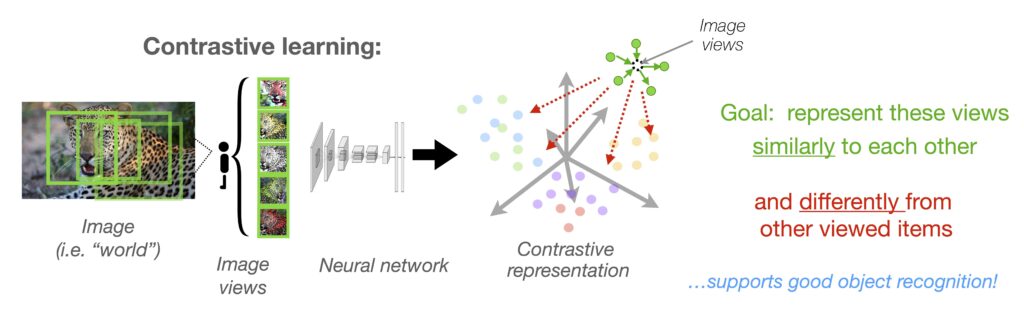
What is contrastive learning?
Imagine training a system to differentiate every single image it sees from every other image—without explicitly telling it what anything in the images are. Over time, this system learns to pick up on key visual features that help distinguish faces from bodies, words from objects, and so on. This is what happens when deep neural network models learn visual representations using self-supervised contrastive learning. The power of this learning setup is that it shows how humans might naturally learn to represent categories simply by being exposed to a diverse set of visual inputs, even before they can understand the names of objects.
Emergent category selectivity without explicit category knowledge
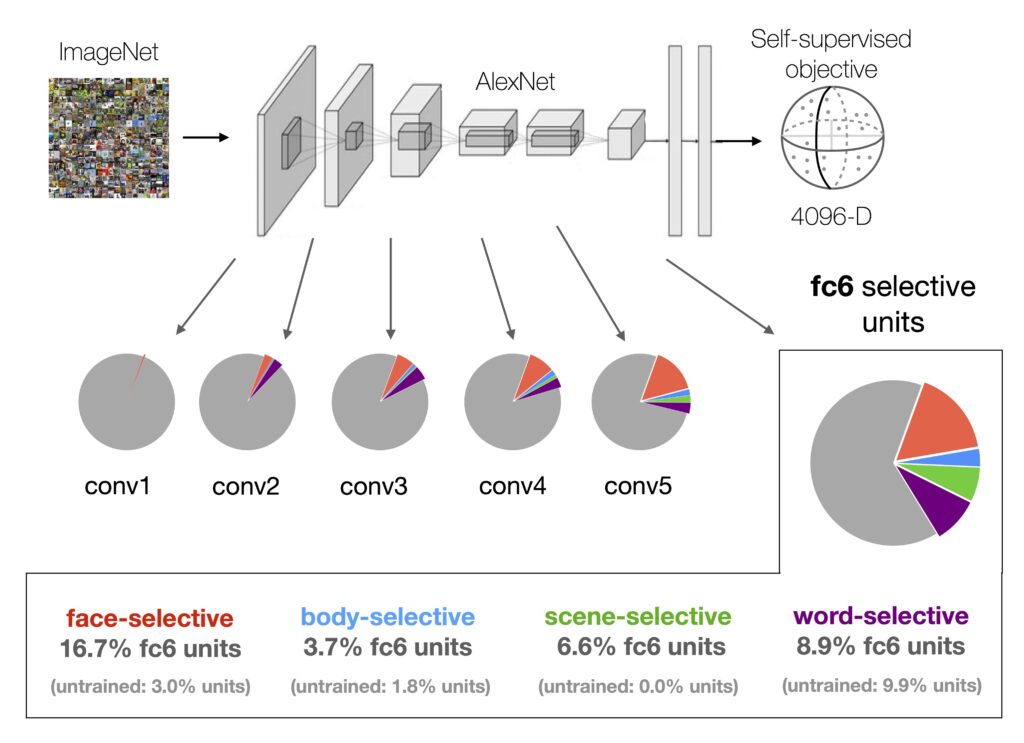
Strikingly, we observed that in models trained on natural images using self-supervised learning (specifically, the Barlow Twins algorithm), distinct groups of units naturally become selective for the key categories of faces, bodies, words, scenes, and objects. These regions parallel the category-selective areas we observe in the human brain, such as the Fusiform Face Area (FFA) or the Visual Word Form Area (VWFA). How did we test this? We recorded how individual model units responded to the same sets of ROI “localizer” images that would be used to define these brain areas in fMRI experiments with humans.
We found increasing numbers of selective units emerging from the input to output stages of the model, paralleling the ventral visual stream. This finding implies that the brain’s selectivity for faces, bodies, places, and words may indeed arise from general learning mechanisms, driven by exposure to a rich array of visual stimuli, rather than requiring domain-specific learning mechanisms.
Lesioning: what happens when we disrupt category selectivity?
To explore the functional role of these category-selective units, we performed a series of lesioning experiments. By selectively silencing face-selective, scene-selective, body-selective, or word-selective units in the model, we were able to quantify the impact on recognition performance.
We found that lesioning face-selective units, for instance, significantly impairs the model’s ability to recognize ImageNet categories that rely heavily on facial features (such as dog breeds). Similarly, lesioning scene-selective units impairs recognition of different places and large object categories. Each lesion induced a dramatically different profile of recognition deficits. This resembles the selective, dissociable impairments observed in humans with brain lesions to category-selective areas such as FFA. This strongly suggests that even without category-specific training, these units play a critical role in the model’s ability to differentiate between categories, just as the category-selective brain areas do in humans.
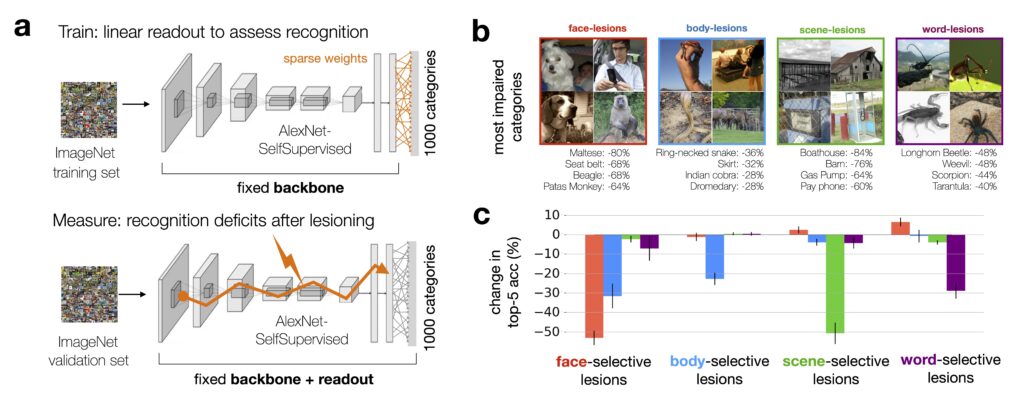
These results challenge the idea that recognizing an object requires consulting the entire population of neurons – a fully distributed code. Instead, the selective recognition deficits following targeted lesions indicate that some units play a more critical role than others.
Measuring representational alignment to the human brain
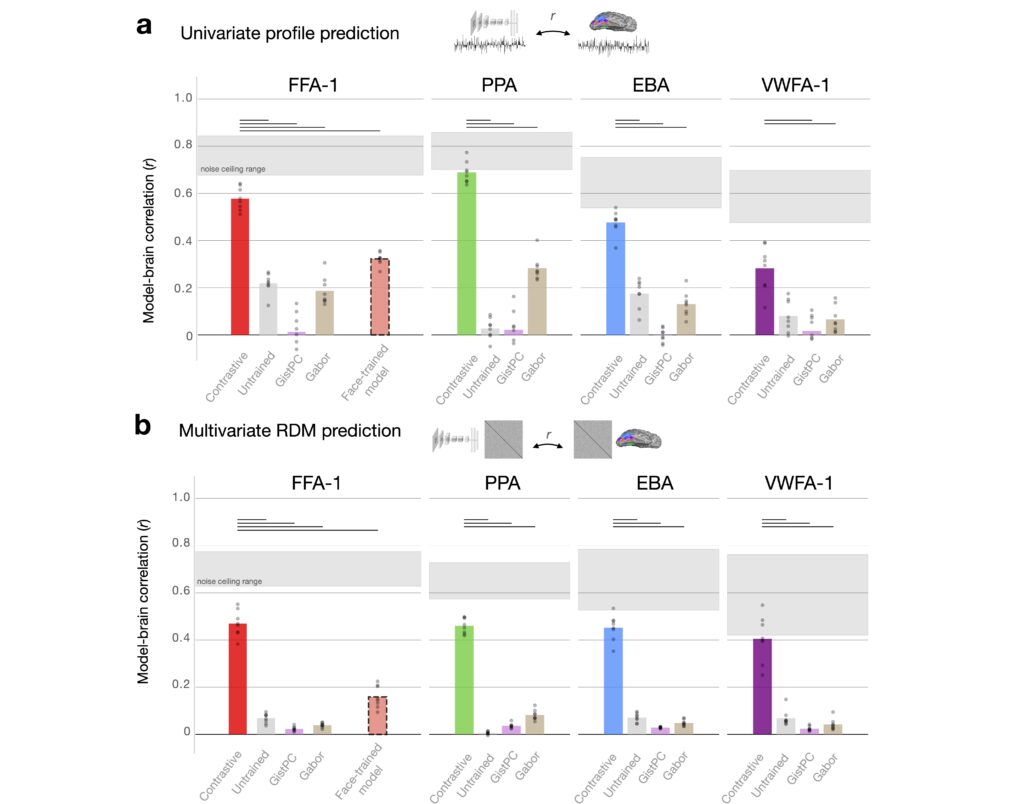
We next sought to test the predictive capacity of the emergent category-selective units by comparing them to real neural data. To do this, we used the Natural Scenes Dataset (NSD), a massive fMRI dataset consisting of brain responses from participants viewing thousands of natural scenes. NSD offers the highest quality large-scale dataset available for linking brain activity to complex visual inputs, making it the ideal resource to test how well our self-supervised model aligns with the brain’s visual system.
We mapped the model’s emergent category-selective units to the fMRI responses using a biologically motivated sparse-positive linear regression model. This approach imposes two key constraints: (1) only a small, selective set of units are allowed to contribute to each voxel’s activity, and (2) the regression weights on each unit must be positive. These constraints are necessary to prevent counterintuitive outcomes – such as scene-selective units effectively explaining anticorrelated face-selective cortex. Our procedure instead preserves a meaningful parallel between the selective subsets of model and brain feature spaces.
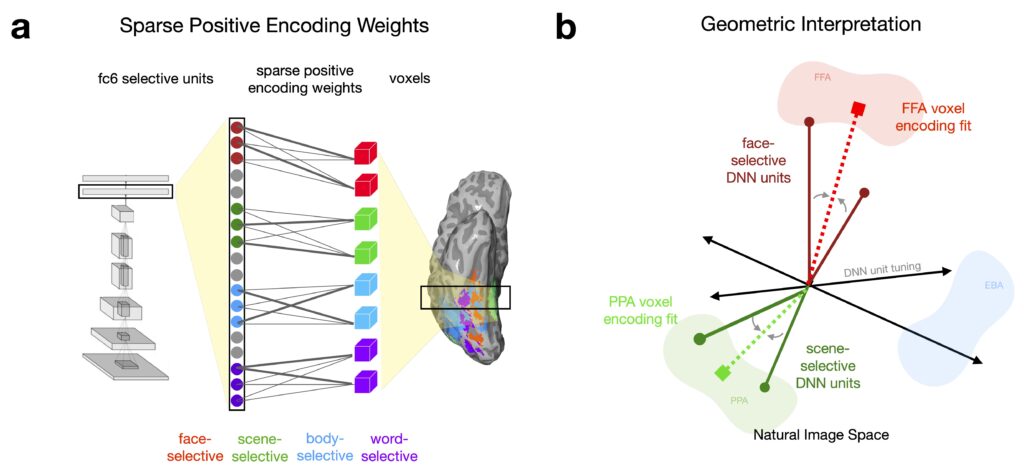
We found high correlations between the predicted and observed responses across the full suite of category-selective ROIs. Critically, for prediction of face-selective regions, the contrastive model also achieved significantly higher predictivity than a category-specialized model trained only to recognize over 3000 face identities. These results demonstrate that the category-selective representations in our model closely mirror those observed in the human brain, offering strong evidence that contrastive learning captures the key tuning axes underlying category selectivity.
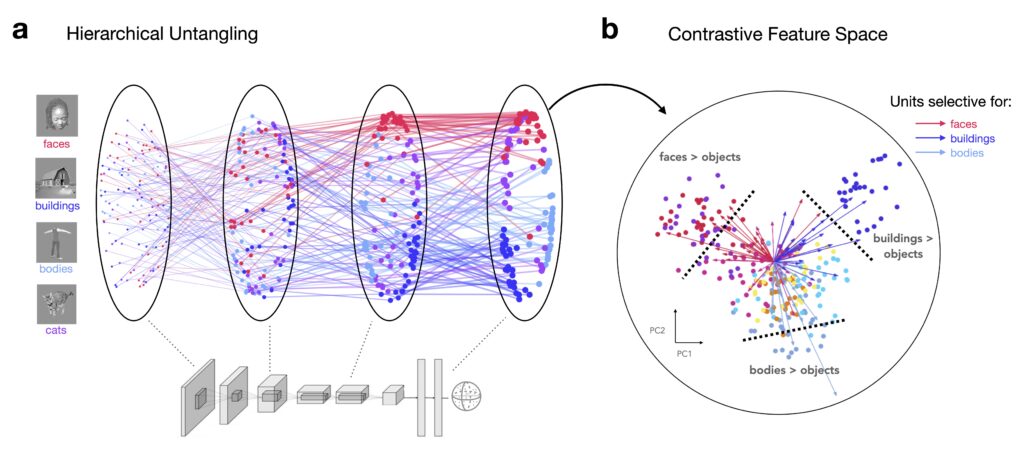
Learning to untangle object categories from a rich visual diet
At the input level (pixels), object categories are tightly interwoven in representational space, with little distinction between them. We observe that contrastive learning models successfully untangle visual categories by pushing apart similar inputs and pulling together different views of the same object. This learning mechanism doesn’t require predefined rules for categories like faces, bodies, or places. Instead, by simply learning to differentiate between a wide variety of natural images, the model gradually organizes visual inputs into distinct axes along which categories become more separable.
As you move deeper into the network’s layers, these categories become more pronounced. Representations of faces, bodies, and objects start to form distinct clusters, separating themselves out from other categories. This process reflects how the model learns to efficiently encode and structure the visual world, organizing information in a way that allows different categories to “stick out” in the feature space.
This untangling of visual categories shows how general-purpose learning can naturally lead to specialized representations, with no need for hardcoded category-specific mechanisms.
A unifying account of visual category selectivity
Our work reveals that diverse category-selective signatures arise within neural networks trained on rich natural image datasets, without the need for explicit category-focused rules. These findings help reconcile the longstanding tension between modular and distributed theories of category selectivity. Drawing on modular viewpoints, we offer that category-selective regions play a privileged role in processing certain types of visual categories over others. Importantly, we show that domain-specific mechanisms are not necessary to learn these functional subdivisions. Rather, they emerge spontaneously from a domain-general contrastive objective, as the system learns to untangle the visual input.
At the same time, our contrastive coding framework provides a computational basis for the hallmark observation of distributed coding theories: that pervasive category information is decodable across high-level visual cortex. This widespread decodability is a direct consequence of contrastive learning, since the emergent tuning in one region shapes and structures the tuning in other regions. However, this does not imply that all parts of the population are causally involved in recognizing all visual entities – distributed representation does not entail distributed functional readout. In recognizing these key distinctions, our work provides a unifying account of category selectivity, offering a more parsimonious understanding of how visual object information is represented in the human brain.