
Boomerang Distillation Enables Zero-Shot Model Size Interpolation
October 29, 2025Real-world deployments of LLMs require models of different sizes to meet performance, latency, and cost targets. Yet pretraining every size is prohibitively expensive, leaving large gaps in size-performance curves. We identify a novel phenomenon, Boomerang Distillation, which occurs when distilling a large language model into a smaller one. In this blog post, we describe how Boomerang Distillation can be used to create entire families of LLMs of fine-grained sizes without any training from a single student-teacher pair.
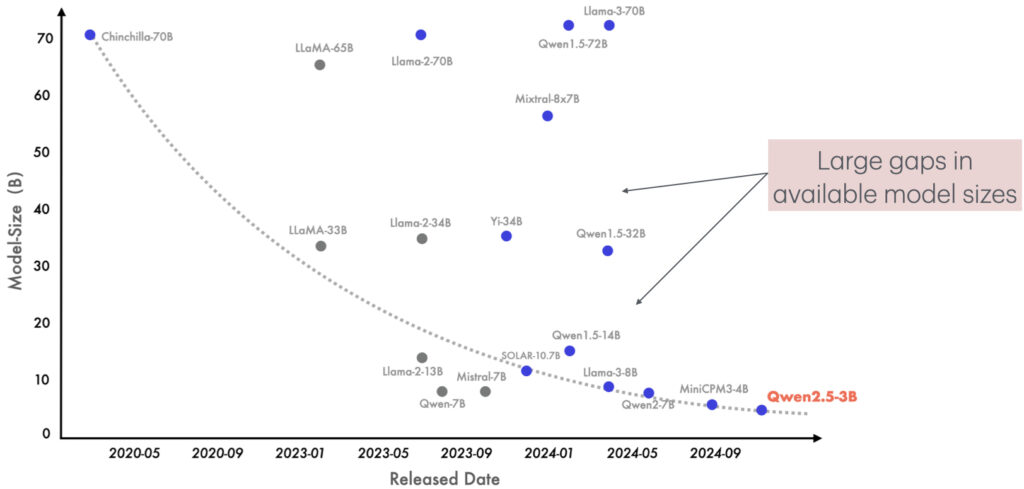
Today’s large language models power everything from chatbots on your phone to massive AI systems running in data centers. But not all devices can handle the same model sizes: a model that’s fast on a GPU cluster might be unusable on a laptop. AI model developers try to solve this by releasing “model families” consisting of different-sized versions of the same model. For example, Llama3 models come in sizes ranging from 1 billion to 70 billion parameters. Yet training each size from scratch is expensive, leaving big gaps between available models. What if we could fill those gaps without any extra training? That’s exactly what we explore with Boomerang Distillation, a new way to “recombine” parts of large and small models to create many intermediate sizes – all from a single training run.
Current approaches for training LLM families are computationally expensive
As training each model size from scratch is very computationally intensive, many modern LLM families start with one large pretrained model (the teacher) and distill it into smaller ones (the students). This procedure is called knowledge distillation. Typically, the student models learn with the usual next-token prediction objective, plus extra losses that make them imitate the teacher’s behavior (e.g. KL divergence and cosine distance). Distillation is more compute-friendly than training every model without a teacher, but it still requires training each model independently on up to a trillion tokens. This expensive process limits how many models developers can release, so we typically end up with a small set tuned for common GPU setups. Meanwhile, practitioners need models tailored to their hardware and compute budgets. Unless they train a new model themselves, they’re limited to a few prebuilt options, leaving large gaps in the trade-off between model compute and performance (Figure 1).
Boomerang distillation: creating multiple models for the price of one
Given the limitations of current approaches, how can we efficiently create models of different sizes? We show that surprisingly, distillation is not just useful for training good student models – with the right setup, we can mix and match parts of the teacher and student models to build intermediate models that smoothly trade off size and performance! We call this phenomenon boomerang distillation: starting with a large teacher, we distill a single smaller student, and then “boomerang” back toward the teacher by selectively swapping in teacher components, creating many models of intermediate size without any additional training.
Intuitively, boomerang distillation works because we encourage each student layer in the distilled model to approximate the function of some block (contiguous set) of teacher layers. In this setup, each student layer can be thought of as a compact summary of one or more teacher layers. Then, swapping out a layer in the student and replacing it with its corresponding block of teacher layers produces a larger model with a better approximation of what the student is trying to compute. Each swap increases model size and improves similarity to the teacher, producing a new, usable model with no extra training required.
Boomerang distillation consists of three key steps: (1) student initialization, (2) knowledge distillation, and (3) student patching (Figure 2). We explain each of these steps in detail below.

Step 1: Student initialization
We start aligning student layers to teacher blocks (a “block” is one or more contiguous teacher layers) by initializing the student with layers copied from the teacher (Figure 2, left). This creates a clean mapping: every student layer should stand in for a specific teacher block.
For example, in Figure 2, we copy layers 1, 3, and 5 from the teacher to create the student. Then,
- The first student layer S1 maps to teacher layers T1 and T2
- The second student layer S2 maps to teacher layers T3 and T4
- The third student layer S3 maps to teacher layer T5
Copying gives us a strong head start, since each student layer behaves like the first layer in its corresponding teacher block.
Step 2: Knowledge distillation
Once we have the student initialized, we train the model using knowledge distillation (Figure 2 center). To improve student performance, we use cross entropy loss for next token prediction and KL divergence loss to make the student’s predicted probabilities match those of the teacher. We also add a cosine distance loss between the outputs of the student layers and their corresponding teacher blocks.
Continuing the example from Figure 2 above, we align
- S1 with T2’s output (for the T1-T2 block)
- S2 with T4 (for T3-T4)
- S3 with T5 (for T5)
This layer-to-block alignment trains each student layer to mimic the computations in its mapped teacher block.
Step 3: Student patching
After distillation, we can assemble models of many sizes by patching student layers, i.e., replacing any student layer with its corresponding block of teacher layers (Figure 2, right). Because we enforced layer-wise alignment in Steps 1 and 2, each swap creates an intermediate model that better approximates the teacher.
In our example from Figure 2, we can choose any subset of swaps:
- Replace S1 with T1-T2
- Replace S2 with T3-T4
- Replace S3 with T5
Choosing different combinations of swaps yields intermediate models of different sizes, giving a smooth menu of compute/accuracy trade-offs without additional training.
Boomerang distillation interpolates between student and teacher performance
What are the necessary conditions for boomerang distillation to succeed?
To probe when boomerang distillation works, we run two simple stress tests. First, we study whether a student that’s randomly initialized (instead of copying layers from the teacher) could still yield useful intermediate models. Second, we try naive pruning: initialize the student from teacher layers, but skip the distillation step entirely.
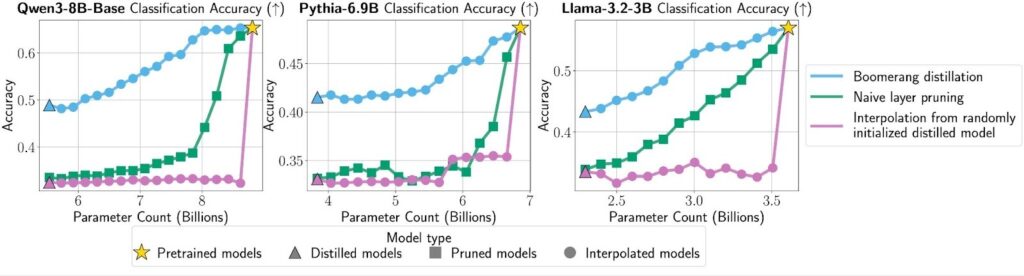
We find that across multiple model families and sizes, boomerang distillation creates intermediate models whose performance interpolates smoothly between the student and teacher (Figures 3 and 4). In contrast, both baselines’ performance sharply decreases with model size. This shows that both ingredients – the right initialization and knowledge distillation – matter. Leave out either step and the boomerang effect largely disappears.
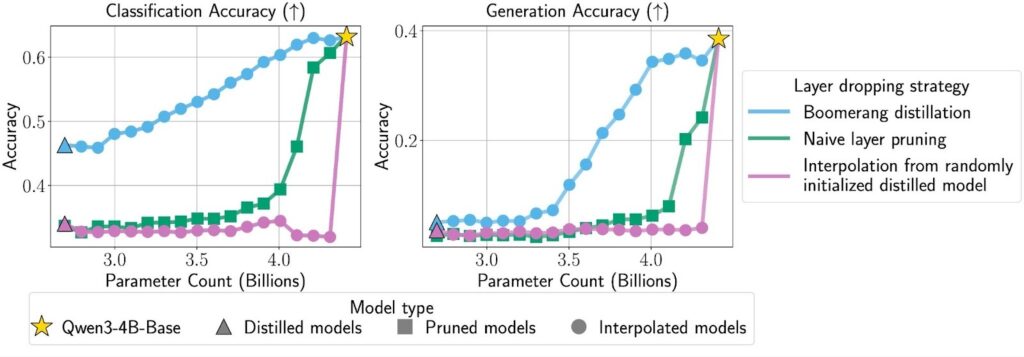
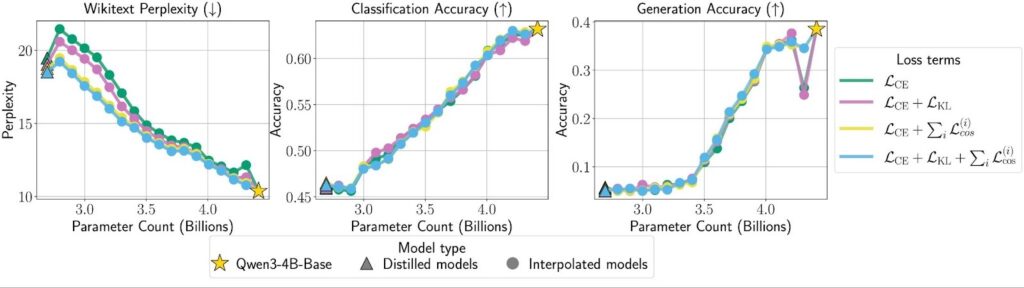
We also test which parts of the distillation objective are needed for boomerang distillation. To do so, we train four students with ablated loss terms and then interpolate from them. In Figure 5, we find that for most model sizes, leaving out the per-layer cosine distance (the green and purple lines) does not meaningfully reduce interpolation performance. This suggests that the initialization in Step 1 already provides enough alignment for boomerang distillation to work reasonably well without explicitly training every intermediate layer to match the teacher. That said, students distilled with the per-layer cosine term show more stable interpolation than those without. Looking ahead, we are interested in understanding whether we can keep that stability without explicit layer-wise alignment during distillation, because removing the need to keep the teacher in memory would significantly reduce the GPU footprint of training the student.
How good is boomerang distillation?
Comparison to standard distilled models
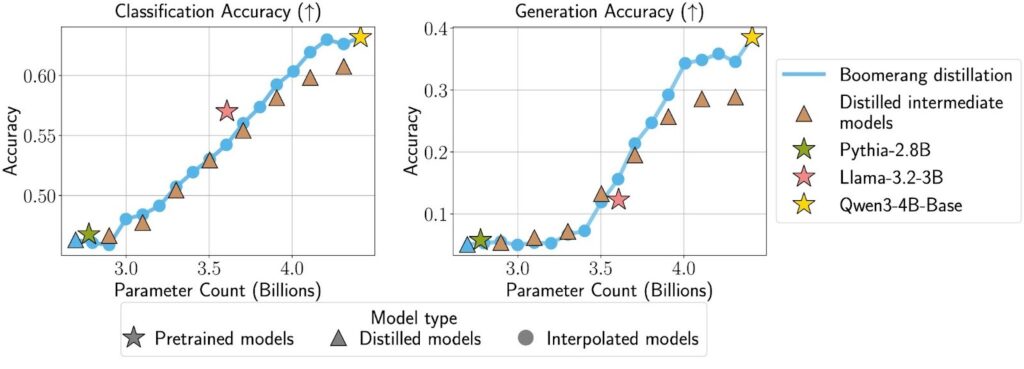
Now that we have interpolated models from boomerang distillation, we compare them to same-size models trained with a standard distillation objective. For an apples-to-apples test, we use the same initialization and distillation setup as the small student model.
We find that boomerang distillation creates intermediate models with performance on par with standard distilled models of the same size, even outperforming them at larger sizes (Figure 6). In practice, this means we only need to distill a single student to get a full lineup of intermediate models that perform similarly to models individually distilled with the same token budget. These interpolated models also stack up well against pretrained models like Pythia-2.8B and Llama-3.2-3B, which train on far more tokens than the student.
We also observe that knowledge distillation can hurt models like Qwen at larger sizes (toward the right of Figure 6), likely because they originate from proprietary, high-quality data; retraining on public data (of presumably lower quality) can cause a drop in performance. With boomerang distillation, we mitigate this issue because we interpolate directly between the student and the teacher.
Comparison to layer pruning
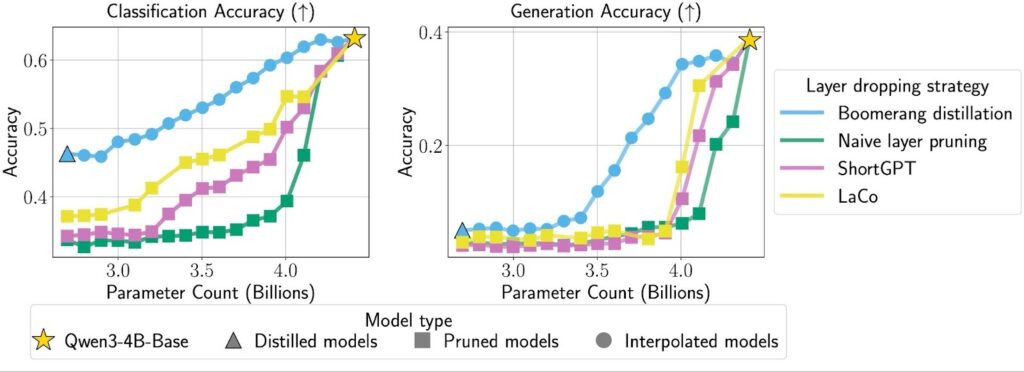
How does boomerang distillation compare to smart layer pruning methods? Layer Collapse (LaCo) and ShortGPT are popular approaches that look for redundancy in a transformer and drop entire layers to shrink the model without training.
In practice, boomerang distillation exhibits much better performance. As Figure 7 shows, its interpolated models consistently outperform layer-pruned models of the same size, and the gap widens as models get smaller. This is likely because boomerang distillation blends information from both the distilled student and the original teacher, so the intermediate models can use information from both models. Pruning, by contrast, compresses only the teacher; once you shrink far below the teacher’s size, quality tends to fall off.
Future directions
We introduce boomerang distillation, a simple recipe for training-free creation of intermediate-sized language models: start with a big teacher model, distill a compact student, then mix and match student and teacher layers to build models that smoothly scale in size and performance. We are excited by the potential of boomerang distillation to shift how developers create model families. Instead of training many models from scratch, they can simply distill one student and then interpolate, swapping in teacher blocks as needed to produce a full lineup that covers different accuracy-latency targets. This opens the door to finer-grained LLM customization for real-world constraints. Looking ahead, extending these ideas to pretraining-scale token budgets and into other domains (such as vision) can build model families tailored to a wide range of deployment settings.