
This blog is adapted from
One fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity
Alignment Reduces Conceptual Diversity of Language Models
February 10, 2025As large language models (LLMs) have become more sophisticated, there’s been growing interest in using LLM-generated responses in place of human data for tasks such as polling, user studies, and behavioral experiments. If possible, using a synthetic replacement for the process of human data collection could be transformative for a variety of human factors disciplines, from political science to economics and psychology.
While prior work suggests that LLMs can capture certain behavioral patterns, there are ongoing debates as to whether they are valid replacements for human subjects. In domains like cognitive science, the question of whether synthetically-generated LLM “populations” can accurately simulate the responses of human populations requires understanding the extent of their ability to capture the conceptual diversity of heterogeneous collections of individuals.
These issues of models’ output diversity are further complicated by the prevalence of post-training alignment techniques such as reinforcement learning from human feedback (RLHF) and reinforcement learning from AI feedback (RLAIF). These techniques are now standard parts of LLM development, and presumed to contribute to the human-like abilities of models, but have also been shown to induce biases that can limit the lexical and content diversity of their outputs.
In our recent work, “One fish, two fish, but not the whole sea: Alignment reduces language models’ conceptual diversity”, appearing at NAACL 2025, we use a new way of measuring the conceptual diversity of synthetically-generated LLM “populations” to investigate two related research questions:
(1) Do modern LLMs capture the conceptual diversity of human populations, i.e., individuals’ variability in conceptual representations?
(2) How does post-training alignment (here, RLHF or RLAIF) affect models’ ability to capture this feature of human response distributions?
Using LLMs to simulate human subjects in behavioral research
Recent works have proposed using LLMs as stand-ins for humans in many applications and domains, including opinion surveys and polling in political science, user studies in human-computer interaction, annotation tasks, and various economic, psycholinguistic, and social psychology experiments. While several works have responded by identifying LLMs’ lack of answer diversity as a potential limitation of using LLMs in these applications, these works have largely focused on whether models are capable of capturing demographic- and subgroup-level variation in settings where accurately simulating the social identities of a human population of interest is directly relevant to the task.
These works propose two main techniques for manipulating the “diversity” of responses generated by models to simulate unique individuals: increasing the softmax temperature parameter, and conditioning on different types of contexts that include individuals’ demographic or social identity attributes. In our experiments, we simulate and evaluate populations of unique individuals in LLMs using these two inference-time techniques.
Concerns about the effects of alignment on LLMs’ content diversity
Post-training alignment techniques such as RLHF and RLAIF are now standard parts of LLM development. However, it has also been observed that “aligned” models show biases that can limit the lexical and content diversity of their outputs. It also remains unknown whether alignment to synthetic preferences (instead of human preferences) might worsen these biases, as it is possible these models “collapse” when recursively trained on synthetically generated data. Our experiments are designed to further investigate this potential for diminished diversity in LLMs’ outputs due to the techniques that are presumed to contribute to their human-like abilities.
A new way of evaluating conceptual diversity in model generations
A natural way to study conceptual diversity is to study the variability in LLMs’ response distributions at the population level – that is, by considering averages across simulated individuals. However, assessing population-level variation without individual-level variation can mask important information about the population, particularly whether it is homogeneous (comprised of individuals who share similar underlying representations) or heterogeneous (comprised of individuals with meaning-fully different representations).
To address these gaps, we evaluate ten open-source LLMs on two domains with rich human behavioral data: word-color associations, and conceptual similarity judgments. While there is no single agreed-upon metric for capturing conceptual diversity, we consider two different metrics that relate the internal variability of simulated individuals to the population-level variability in their respective domains.

The first domain probes people’s intuitive associations between words and colors, building on the experiments of Murthy et al. (2022). In this task, human participants were presented with a target word (such as “chalk” or “obligation”) and asked to click on the color most associated with the word, from a set of 88 color chips. Participants were tested in two blocks, ultimately providing two color associations for each word. This design enables measures of population variability (how much color associations vary across individuals) as well as internal variability (how much they vary in an individual’s own representation).
The second domain, inspired by Martí et al. (2023), probes the number of latent concept clusters in a population. In this task, participants were asked for similarity judgments between concepts in a particular category (e.g., “Which is more similar to a finch, a whale or a penguin?”). Two categories were tested: common animals, which are more likely to have shared conceptual representations across individuals; and United States politicians, which are likely to have varying representations across individuals. We analyze the responses using a Chinese Restaurant Process model to obtain the number of clusters (i.e., concepts) for each word, allowing us to get the probability of multiple conceptual representations in the simulated population.
Our findings
We compare the conceptual diversity achieved by models against that of humans, and specifically examine the effect of alignment on the degree of fit between models and humans. We evaluate two popular methods for eliciting unique individuals from LLMs – temperature and prompting manipulations – in two domains and find that adding noise in the form of unrelated and randomly shuffled prompts does more to increase model diversity than persona prompting and temperature manipulations. Still, we find that no model approaches human-like conceptual diversity. Further, our results suggest that alignment to synthetic or human preferences (in the form of RLAIF and RLHF) flattens models’ conceptual diversity in these domains, compared to their base or instruction fine-tuned counterparts.
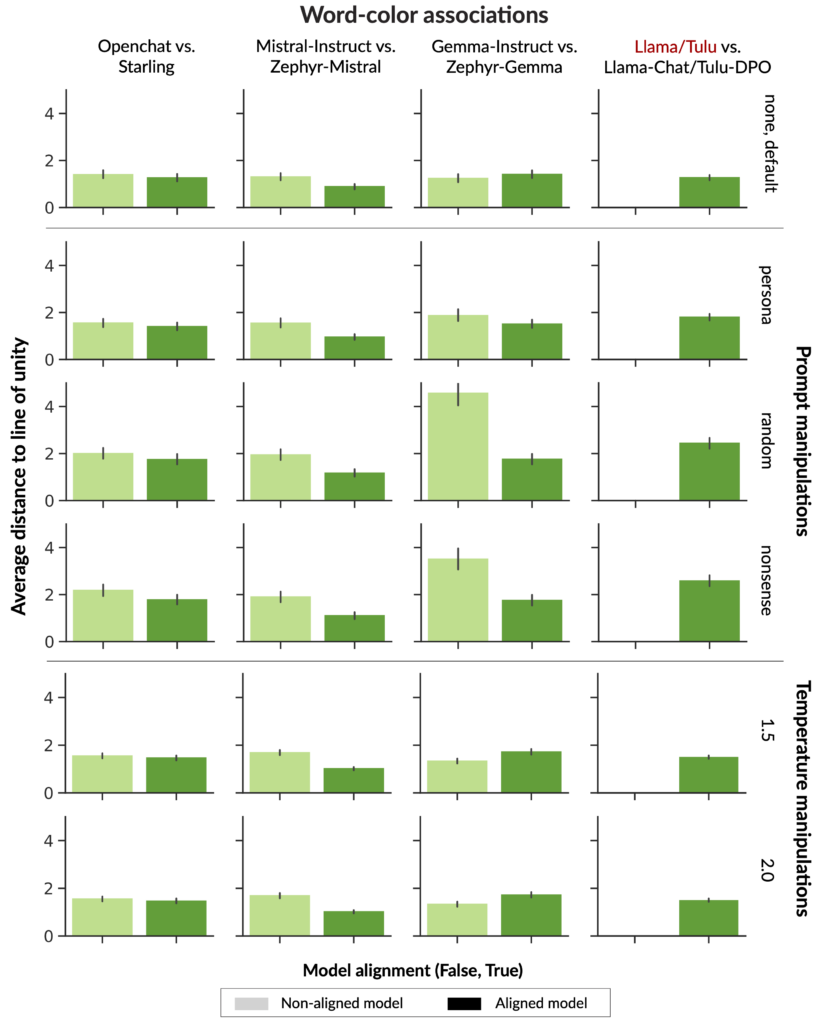

Our findings corroborate those of recent work in many domains that suggest that injecting variability in models’ outputs through temperature and prompt manipulations does not do enough to induce meaningful variability on relevant metrics, and often just leads to highly incoherent outputs. One reason for this could be that increasing the entropy of the output distribution or conditioning on highly surprising tokens will increase models’ uncertainty over subsequent tokens in a domain-general sense. Exploring more task-specific methods for injecting structured randomness into models’ generations could help LLMs to overcome their population- average behavior in ways that more meaningfully simulate the cognitive differences in human individuals.
This raises further questions of what factors give rise to individual differences in humans and whether these are the same attributes that can result in individual-like models. While it is common to obtain a representative samples of a human population for studies in cognitive science using identity attributes like gender or race, the identity-level representations of people that are most easily replicated in post-training methods likely do not capture the reasons for the differences in people’s conceptual representations. Exploring corresponding notions of context-specific cognitive or computational resources (e.g., working memory) in models could allow them to serve as testbeds for theories of individual differences in humans (cf. Hu and Frank, 2024).
Overall, our results suggest that there may be trade-offs between increasing model safety in terms of value alignment, and decreasing other notions of safety, such as the diversity of thought and opinion that models represent. Still, we find that regardless of model variant, popular techniques for simulating the response distributions of unique individuals do not do enough to induce human-like conceptual diversity in models’ outputs. Our findings urge caution that more work needs to be done to improve meaningful diversity in models’ generations before they are used as replacements for human subjects, or deployed in human-centered downstream applications.