
From Lab Rats to Chatbots: On the Pivotal Role of Reinforcement Learning in Modern Large Language Models

Generative large language models (LLMs), such as ChatGPT, are primarily trained using self-supervised learning. Reinforcement learning (RL) is used afterward to fine-tune the model’s responses according to human feedback.
Image: Adobe Stock
The explosion of modern AI, exemplified by the unprecedented abilities of large language models (LLMs), was enabled by a family of computational techniques known as machine learning (ML). But how exactly does a machine learn anything? In this explainer, we dive into one of the most important tools in the ML toolbox: reinforcement learning (RL).
The prehistory of RL: B.F. Skinner and operant conditioning
In the middle decades of the 20th century, B. F. Skinner was one of the most influential experimental psychologists in the world. A Harvard professor, Skinner is widely considered the father of operant conditioning, a technique for training an animal or a human to produce a specific behavior using rewards or punishments. It’s the same approach a dog owner might use to train a dog by rewarding certain behaviors with treats.
While still a graduate student, Skinner invented the operant conditioning chamber or “Skinner box,” a highly controllable setting in which a lab animal’s behavior can be observed and manipulated. A rat in a Skinner box might be given a treat whenever it happens to press a lever after a light is turned on. Over time, the rat learns to tap the lever as soon as the light turns on. Alternatively, the rat might be punished for tapping on a lever. Over time, the rat learns to avoid that action. In both cases, the rat learns what to do, and what not to do, by trial and error. Over time, the rat’s voluntary behavior is shaped by the consequences of its past actions.
A rat running around in a cage tapping on levers might seem a world away from a large language model running on a state-of-the-art supercomputer like the Kempner AI cluster, but there’s an important thread linking Skinner’s work with the ongoing AI renaissance.
Operant conditioning involves using rewards and punishments to strengthen or reinforce specific actions, rendering those actions more likely to be chosen. Nowadays, the study of operant conditioning in the context of computational modeling is known as reinforcement learning (RL). Much like rats in a Skinner box, today’s high-tech large language models learn how to make decisions—or are “trained”—through reinforcement learning.
Training a computer program using an RL algorithm is conceptually quite similar to training a rat using operant conditioning. A computer program trained using RL is typically referred to as an “RL agent.” First, the agent tries out an action at random. In response to that action, it receives a reward or punishment. Over time, the RL agent figures out which actions are most likely to be rewarded, and which are most likely to be punished. The agent tends to choose the best action in any circumstance, and this is how the program “learns” how to make decisions that lead to the desired outcome.
Pre-training LLMs with supervised training

Training a language model involves several stages of which RL is typically the final stage. When looking at the trajectory of LLMs, RL has emerged as the decisive innovation in elevating LLMs from interesting curiosities to revolutionary technologies.
The first stage in training a language model is called “supervised learning.” Given a string of input text, a generative language model is asked to predict the next word, or more accurately, the next token, which can be a short word or a portion of a word. [See sidebar: Tokens vs Words]. Initially, the model just guesses what the next word might be. The training algorithm then computes the error, which is a measure of the discrepancy between the guess and the actual word.
This kind of training is called “supervised” because the model is always shown the correct answer at the end: it learns to improve based on how far it was from the correct answer. This distinguishes supervised learning from RL. In RL, the model isn’t shown the correct answer but instead receives a reward or a punishment depending on its answer.
Models that have been trained using supervised learning are often referred to as “pre-trained” because they receive this answer-based training prior to RL training. A prominent example of a pre-trained model is OpenAI’s GPT class of models. GPT stands for Generative Pre-trained Transformer.
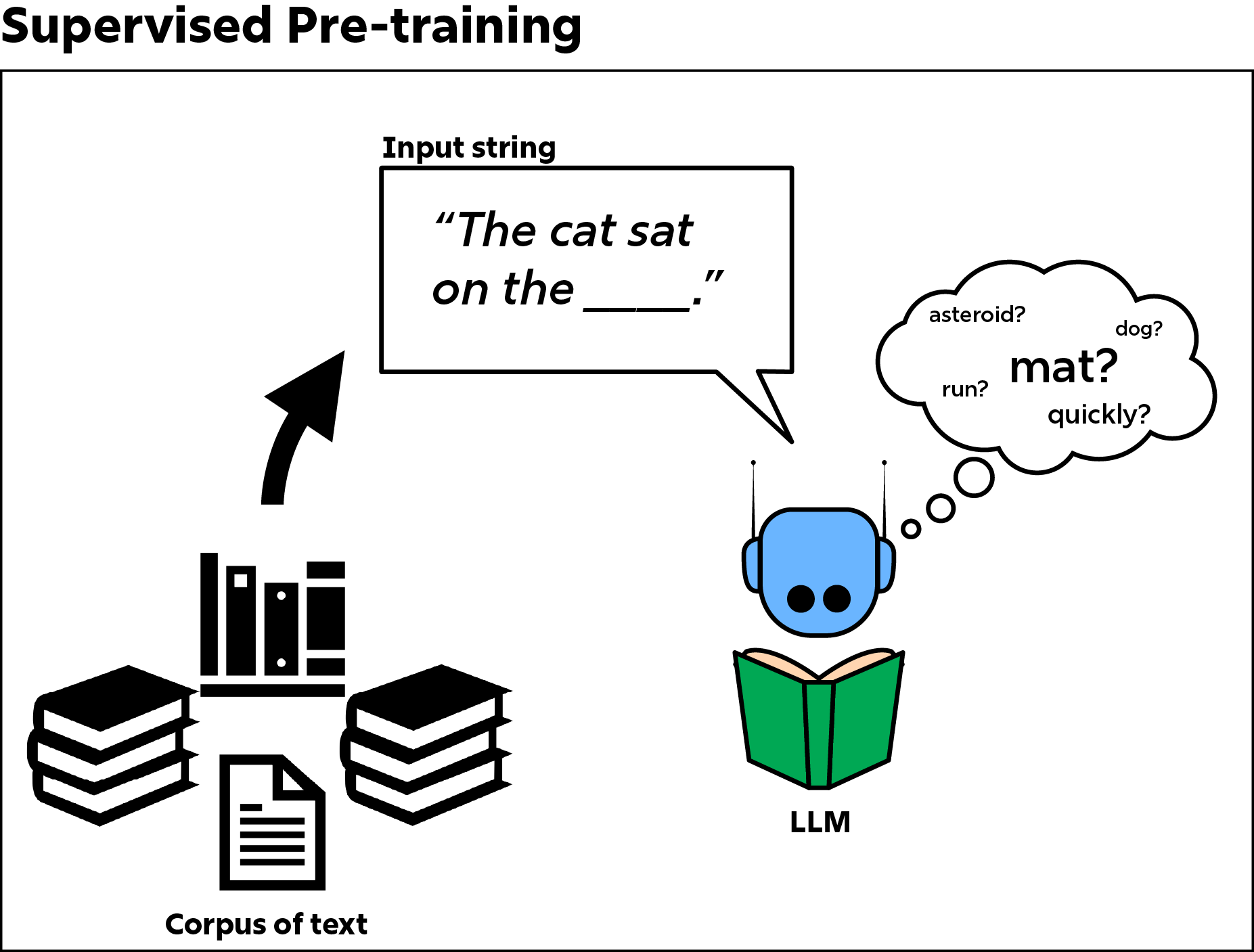
Supervised learning involves showing the model a dataset of input strings where the final word is left out. The dataset is like a long list of fill-in-the-blank exercises, with the blanks always at the end. Early models trained only with supervised learning methods produced nonsensical strings of phrases. But by scaling up the size of the dataset as well as the size of the model, performance started to improve. GPT-2 could produce grammatically correct sentences. Very few people would call it intelligent, however, given that it lacked the ability to reason or produce factual statements reliably. The outputs of GPT-2 lacked long-range coherence, sounding more like surreal performance art than something useful.
The next iteration of GPT showed marked improvement. GPT-3 was a much bigger model than GPT-2 and was pre-trained with an even larger dataset. It could produce long stretches of meaningful, coherent text, and even imitate the prose style of different authors. The only issue was that it wasn’t yet clear that the general public could find uses for this. Generating ‘likely’ text was fascinating, but still wasn’t fully clear how such technology could be applied in the real world.
Researchers eventually developed another stage of supervised learning called “instruction fine-tuning,” to help make LLMs a little more useful. In this stage, the LLM is exposed to a more structured dataset in the form of instructions (which are usually called “prompts” now), followed by answers. The LLM learns how to follow instructions by receiving feedback on its performance to various prompts. With supervised pretraining and instruction fine-tuning, an LLM could answer questions and follow instructions. But the responses still weren’t consistently accurate or helpful.
How RL unlocked the potential of LLMs
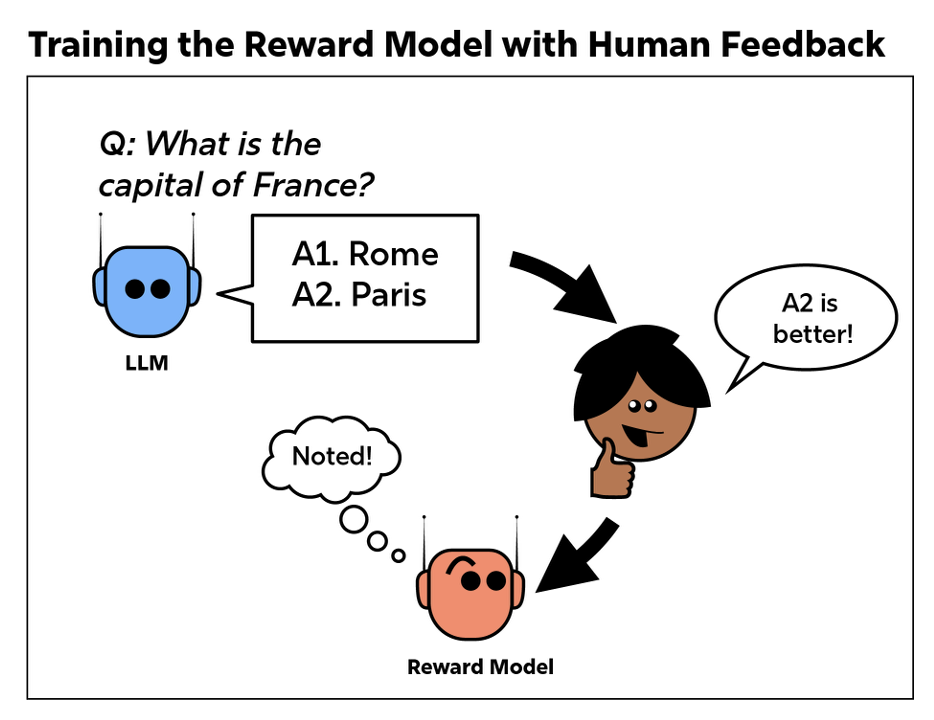
This is when RL made its dramatic entry into language modeling. Researchers at OpenAI figured out that they could use rewards and punishments (in the form of quantitative feedback signals to the model) to tweak GPT-3’s outputs. This process is known as RLHF: reinforcement learning via human feedback. As part of an RLHF session, a human user might be shown two possible responses to a prompt from a pre-trained LLM. The user is asked to pick the one that seems more helpful or accurate. This kind of human feedback enables the construction of what is known as a “reward model,” a model that mimics human preferences.
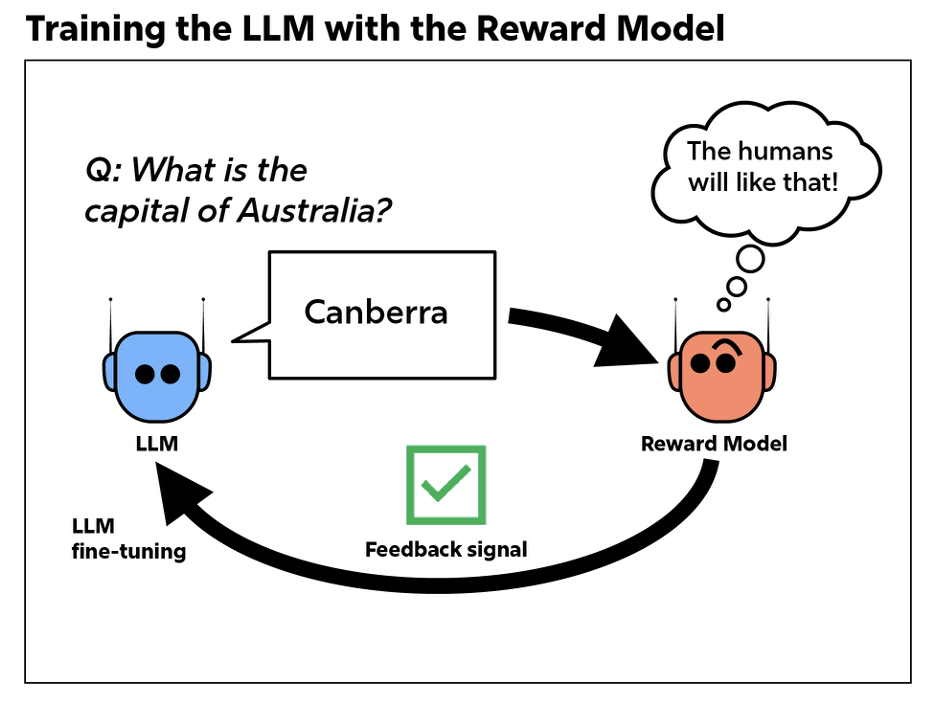
The reward model is then, in turn, used to train the LLM by rewarding answers in line with human preferences. The reward signal takes the form of a score for each answer generated by the LLM. A higher score means a better answer. With enough of this type of quantitative feedback, a pre-trained LLM can gradually be nudged towards useful behavior. In effect, RLHF is a Skinner box to train LLMs: instead of a rat tapping a lever in response to rewards and punishments, a language model outputs answers to text prompts.
RLHF was central to the transition from GPT-3 to ChatGPT. Even for close observers of the evolution of LLMs, ChatGPT represented a startling leap in quality. Its responses to prompts were relevant and often useful, whereas earlier GPT models tended to produce responses that were off-topic or just plain weird. Since the launch of ChatGPT in 2022, an LLM-powered revolution has been underway. Few areas of human activity have been left untouched by this technology: companies and research groups are developing LLM-powered AI tools for everything from finance to medicine to law.
BF Skinner understood the power of RL to nudge behavior in desirable directions. Still, it’s easy to imagine that if he were alive today, even he would be astonished by how successful RL has proven to be for artificial intelligence.
RL research at the Kempner Institute
Kempner Institute researchers are working at the cutting edge of RL, across the full scientific spectrum from theory to practical applications. The projects listed below offer a partial snapshot of the breadth of RL research by the Kempner community, which ranges from innovative new RL algorithms to the use of RL in medical technology.
- Developing new strategies with backtracking: A team including graduate student Tian Qin, Kempner Institute associate faculty member David Alvarez-Melis, postdoctoral fellow and Kempner research fellow Eran Malach recently published a preprint on the role of backtracking in the training of LLMs. They showed that backtracking in combination with RL can unlock new reasoning strategies. Learn more.
- Getting models to transcend their human trainers: Harvard CS graduate student Edwin Zhang (currently at OpenAI), who worked alongside Kempner research fellows Naomi Saphra and Eran Malach, and Kempner co-director Sham Kakade, used an enhanced version of RL to show that a trained model can sometimes perform better than the human experts that trained it. They labeled this phenomenon “transcendence.” Learn more.
- Amplifying pretrained patterns with RL: A recent project demonstrated how RL amplifies behaviors learned by LLMs in pre-training. The work was led by Kempner graduate fellows Rosie Zhao and Alexandru Meterez, who worked with Kempner co-director Sham Kakade, Kempner associate faculty member Cengiz Pelevan, Kempner research fellow Eran Malach, and postdoctoral fellow Samy Jelassi. Learn more.
- Optimizing performance by resetting RL: Kempner Institute Investigator Kianté Brantley and his collaborators are developing the next generation of RL techniques, including the use of resetting to enhance RL agents’ exploration and boost their computational efficiency. Learn more.
- Understanding collective intelligence with multi-agent RL: Kempner Institute Investigator Kanaka Rajan employs a form of RL called multi-agent RL to train collective groups of agents. The goal here is to understand the collective intelligence of hives and swarms. The Rajan Lab is applying these methods to the study of electric fish. Learn more.
- Applying RL to personalized medicine: Kempner associate faculty member Susan Murphy uses RL to train personalized apps to encourage healthy habits like taking medications as prescribed or practicing consistent oral hygiene. These apps learn in real-time using RL-based algorithms, so they gradually become tailored to the specific user. Learn more.
- Enhancing LLM reasoning through self-education: Hugh Zhang, a Kempner graduate fellow working with David C. Parkes, the George F. Colony Professor of Computer Science at SEAS, introduced SECToR (Self-Education via Chain-of-Thought Reasoning), a development of RL training that demonstrates that language models can teach themselves new skills using chain-of-thought reasoning. Learn more.
- Using RL theory to understand prediction: Wilka Carvalho, a Kempner research fellow, and Kempner associate faculty member Sam Gershman are working with collaborators to understand the successor representation (SR) and its generalizations, which are closely related to RL algorithms. The SR and its extensions have been widely employed as predictive representations in engineering contexts as well as in models of brain function. Learn more.
About this series
Kempner Bytes is a series of explainers from the Kempner Institute, related to cutting edge natural and artificial intelligence research, as well as the conceptual and technological foundations of that work.
About the Kempner Institute
The Kempner Institute seeks to understand the basis of intelligence in natural and artificial systems by recruiting and training future generations of researchers to study intelligence from biological, cognitive, engineering, and computational perspectives. Its bold premise is that the fields of natural and artificial intelligence are intimately interconnected; the next generation of artificial intelligence (AI) will require the same principles that our brains use for fast, flexible natural reasoning, and understanding how our brains compute and reason can be elucidated by theories developed for AI. Join the Kempner mailing list to learn more, and to receive updates and news.


