
Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments
April 27, 2026Model-free RL agents trained on simple tasks can be evaluated by whether or not they achieve their simple rewards, but complex open-ended environments demand richer analysis. ForageWorld introduces a naturalistic foraging benchmark where agents must explore, remember food patches, and survive across procedurally generated arenas. In our experiments, naive RNN agents develop structured exploration strategies, multi-factor patch memory, and implicit future planning. These behaviors mirror those documented in foraging insects and rodents and are recoverable only using neuroscience-inspired analysis tools. The approach generalizes across arena sizes, transfers readily to other recurrent architectures, and opens a path toward behavioral and neural transparency in increasingly complex AI systems.
As AI agents become more sophisticated and attempt more complex tasks, it is increasingly important for the field of AI safety to understand what agents are doing to accomplish these tasks and why. For traditional deep reinforcement learning (RL) agents, assessing behavior could be as simple as measuring task performance. Success at a behavior could be quantified by the average reward the agent attained on the task–think maze solve rate, or points scored in an Atari game. This was possible because these tasks were simple, with only one possible strategy to earn a high reward, allowing for clear-cut relationships between skill and outcome: if a classic Atari agent scores well playing Pong, it is “good” at the game, and we can safely infer that it knows how to return the ball consistently.
However, more complex tasks, such as modern video games or naturalistic foraging, offer many viable strategies for achieving “good enough” (if not optimal) rewards. This complexity makes it difficult to identify the larger patterns or skills guiding an agent’s systematic behavior, or to understand what factors in the task caused it to learn that behavior. Consequently, relying solely on reward or other simple metrics (episode time, subtask success rates, etc.) provides an incomplete picture. To holistically understand what these agents “know,” how they learn, or what they will do next, we must look beyond the final score.
How can we gain deeper insight into an agent’s behavior and the neural representations that drive it?
This question has been of major interest to neuroscientists over the last several decades. In pursuit of this, the research community has developed and battle-tested a number of sophisticated analysis techniques that can be applied to both artificial and biological neural networks. In our recent NeurIPS paper “Deep RL Needs Deep Behavior Analysis: Exploring Implicit Planning by Model-Free Agents in Open-Ended Environments,” we demonstrate how these analyses from neuroscience can be applied to a deep RL agent performing a complex simulated naturalistic foraging task.
ForageWorld
We developed a complex yet naturalistic foraging task, dubbed ForageWorld, to evaluate analysis techniques for learning, planning, and the behavior-to-neural activity mapping for these complex tasks. Because these techniques are motivated from the study of animal behaviors and brains while performing the common and well-studied task of resource acquisition, using a computational task that shares the high-level structure of animal foraging allows for the identification of behavior and neural signatures similar to those previously discovered in foraging animals. Successful signature detection would validate the use of these analysis techniques for making non-trivial discoveries about our agent, assuming that agents are using more sophisticated strategies than random walks, for example.
We developed ForageWorld as an extension of Craftax, a challenging recent RL benchmark that was implemented in JAX with GPU acceleration. This architecture allows the environment to run entirely on GPUs alongside the agent model, thus enabling us to train agents on challenging foraging tasks in a reasonable amount of time. ForageWorld is a 96×96 gridworld environment in which the agent must find resources (food and water) while avoiding predators, managing health and sleep needs, and navigating complex terrain. Complicating the achievement of these goals, food appears only in sparsely distributed patches of specific terrain, which deplete over time, as food is consumed, and refill slowly. To survive long-term, agents must learn to identify and remember many food patches and navigate between them over hundreds or thousands of timesteps. As an additional challenge, every time the agent dies from starvation or is killed by predators, it is placed in an entirely new procedurally generated arena with new food and water locations. Thus, the task is not just learning efficient foraging, but also learning how to explore previously unseen, dangerous, large environments.
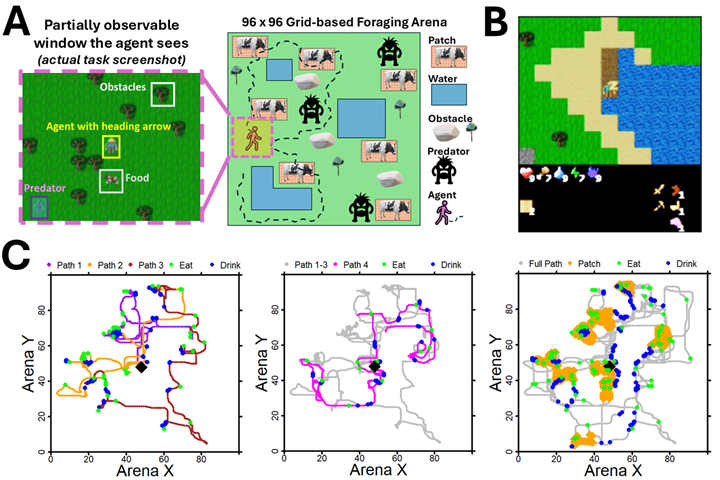
To learn this challenging task, we used a canonical deep RL (DRL) agent architecture, a Gated Recurrent Units (GRU) model trained via Proximal Policy Optimization (PPO). This standard DRL agent is similar to one that is known to perform well on Craftax, and similar models have been used for many other benchmarks and applications. Crucially, we did not assume any biophysically brain-like architecture as a precondition to apply neuroscience analysis tools. The sole requirement was that the model had a time-varying internal state, such as a recurrent neural network (RNN) or transformer model, to generate brain-like activity during task performance and to provide a memory-like module to aid with partial observability. The one domain-specific modification we made to the agent was the addition of a path integration auxiliary objective and corresponding model output head, which requires the agent to track and predict its current position relative to its origin in the middle of the environment (a position tracking capability that most animals and insects do some variant of). We found that this objective induces complex, animal-like behavior in the agent, with significant effects on the model’s internal representation, and improves performance in the largest arena sizes (see below).
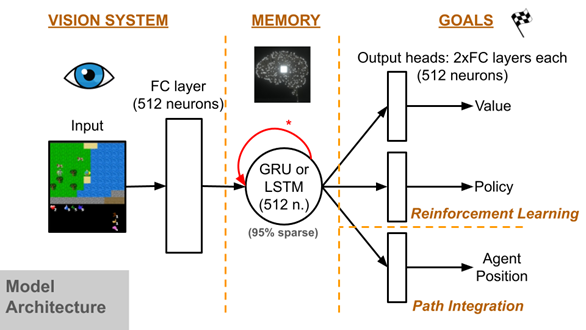
In addition, ForageWorld offers significant utility for computational neuroscience applications, as it has a naturalistic structure while being much more complex than typical comp neuro benchmarks, and is more tractable to analyze than the average neuroAI benchmark, due to its comprehensive neural and behavior logging. Beyond validating standard neuroscience analysis tools for use in machine learning, as demonstrated here, this task also has the potential to validate novel analysis methods in a challenging but simulated larger-world context before applying them in more expensive real-animal experiments. New and better analysis methods are a particularly pressing need for the more complex and continuous data seen in naturalistic neuroscience paradigms.
Analysis
Looking at the performance curves of our trained agent below, we can see that it learned well, but it’s not clear what strategy the agent learned for this task.
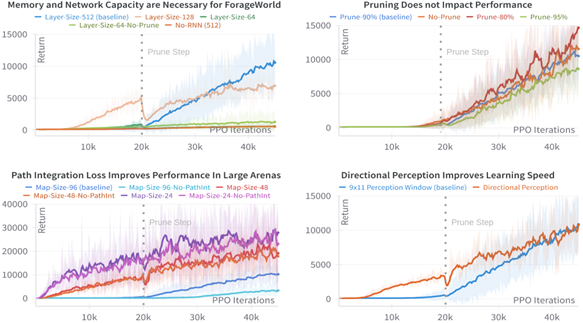
To investigate this, we used several analysis techniques summarized in the following table:

While many neuroAI papers study either behavior or neural activity in-depth, our analysis takes a combined approach. We tried to give comparable weighting to both behavioral and neural analyses, which reflects the real-world interdependence between mechanism and action in biological agents. We used decision models to explore whether the agent was making random or rational patch revisitation decisions after exploration, path and segmentation analysis to study the degree of randomness in exploration paths, neural decoding to look at spatial memory and planning time horizons and accuracy, and GLMs to predict single neural activity from position bins to identify what percentage of the network was being used to encode current position and how the position-encoding neural circuit behaved. This framework allowed us to identify a list of the emergent goals that agents developed naturally in this open-ended task, as well as the behavioral and neural strategies they used to achieve them.
Discoveries
The agent learns an exploration strategy similar to that of foraging insects
Using path segmentation, we can see how the agent’s behavior changes over the course of a single episode. As each episode is a new arena, the agent starts out by performing exploratory loops that depart from the origin and then return to it, with each loop covering new directions until the agent has mapped out most of the arena. Following these exploratory loops, the agent then transitions to primarily moving directly between previously discovered food patches, with reduced but still present exploration (i.e., noisy revisitation), finding new shortcuts or patches sporadically, but looping back to the origin less often in between as it revisits patch locations in memory. This spatial exploration to exploitation transition is similar to the behavior reported for foraging insects (Wehner & Srinivasan, 1981; Clement et al., 2024; Chittka, 2022; Osborne et al., 2013) and rodents (Rosenberg et al., 2021; Lai et al., 2024) which will similarly perform exploratory loops when placed in an unfamiliar environment before transitioning to targeted resource patch exploitation behavior. Again, each new episode the RL agent is placed in contains a totally new and unseen environmental configuration of patches, obstacles and predators.
As our learning objective contains no exploration incentive beyond the demands of survival, we didn’t expect this structured exploration strategy to emerge, and we were only able to discover it thanks to path segmentation and analysis of long trajectories (tens of thousands of timesteps). Its discovery leads one to wonder whether such emergent exploration is actually common in complex RL tasks, at least when recurrent memory is included in addition to feedforward RL.
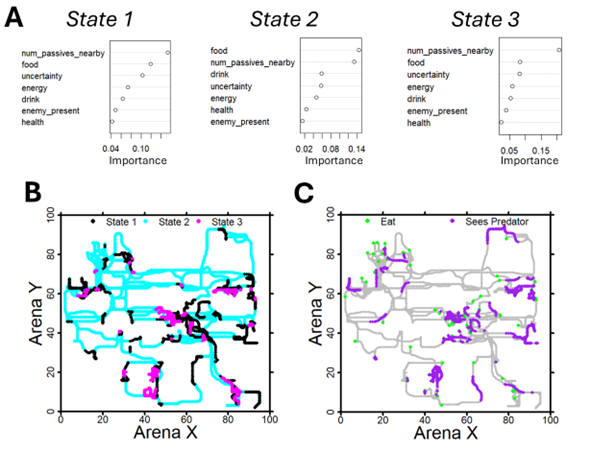
Patch variable histories in working memory and future planning
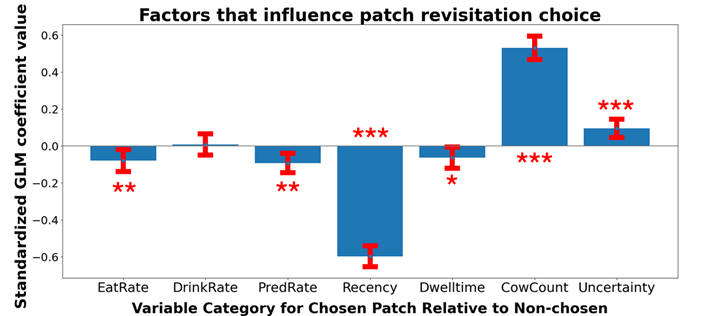
The agent was found to emergently track food patch depletion and abundance in working memory and to plan its future patch revisits up to hundreds of timesteps ahead. We employed a behavioral GLM to investigate which environmental factors drive an agent to return to a previously observed food patch. Specifically, reviewing real-time updates to the values of various patch history variables for each patch previously visited in a given arena. No single factor explained why an agent would prefer one patch over another at a given timestep, but a multi-objective list of several intuitive factors did. For example, the most significant drivers of revisit behavior include recency (more recent is more preferred, maybe due to a clearer memory trace) and historical yield (more cows in previous visits is better). Interestingly, in some runs, agents exhibited a preference for patches associated with higher spatial uncertainty outputted when in them, perhaps to reduce some global uncertainty. This finding says the agent is not simply randomly wandering from patch to patch–it tracks relevant variables over hundreds or thousands of timesteps and uses them to select more desirable patches to visit when hungry, a non-obvious behavior that can’t be seen from simple reward metrics. This question of patch revisitation has also been well studied in the animal foraging literature, and our findings are consistent with the factors reported to influence animal behavior in controlled lab experiments.
Neural signatures of implicit planning
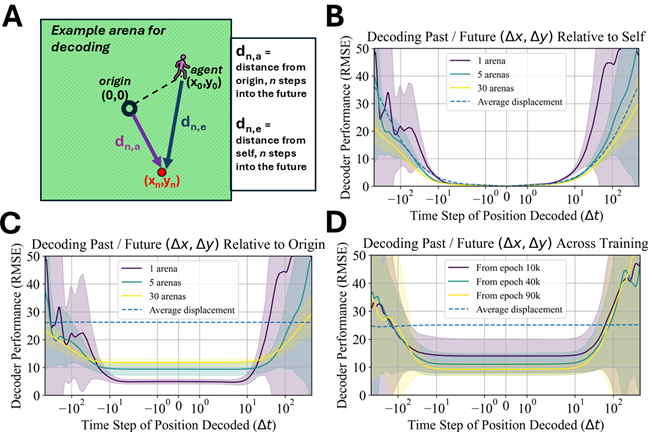
Beyond behavior, we can uncover emergent properties of an agent by looking closely at neural representations. Using an RNN decoding model to probe our agent’s “hidden state”, we evaluated the agent’s ability to reconstruct its past trajectory and predict its future positions. As shown below, the agent surprisingly learns to predict its future position with high accuracy at least 50-100 timesteps into the future–a strong indicator of planning occurring in the model’s hidden state. This is particularly striking because our model lacks any training objective for planning or a forward (e.g., world) model. While prior research has reported emergent planning within RL-RNNs in simpler environments where it was required to perform well at the task, in ForageWorld, agents appear to adopt planning simply as an advantageous, rather than required, strategy. Conversely, memory is empirically required for success in ForageWorld–agents without memory performed poorly and could not survive for long. It’s very difficult to distinguish a model that performs implicit planning from one that doesn’t, using behavior alone–an agent moving towards food could be planning its route or deciding moment-to-moment where to go based on its memory, or following a simple heuristic instead. In animals, there is considerable debate over whether the brain performs an explicit planning process (and in which brain regions). Our findings suggest that the presence or absence of a planning process might not be a binary question, with the potential for implicit planning to occur in diverse brain regions alongside other computations. Powerful but simpler RNN-based planning can occur without advanced world models.
Implications
ForageWorld provides researchers with a publicly available toolkit for probing complex behavior and neural representations. Our findings and methods offer an easy, approachable path forward for both experimentalists and theorists to test out spatial and behavioral navigation experiments in silico, using our simple agents. We encourage colleagues to continue developing the methods presented in this work to better understand agent behavior and neural activity.
The methods and findings from this work also open new avenues for exploring how complex, multi-agent dynamics influence behavior. Neural and behavioral transparency is critical for understanding social agents, where behaviors are, by nature, complex and hard to interpret due to co-adaptation between different agents. We hope to investigate these and other directions to build on our findings here, including by adding multi-agent interactions, both competitive and cooperative. As AI models increasingly interact with real-world contexts, we believe that findings like these can help guide the development of in silico agents with the short-term memory, navigation, and exploratory search abilities required to navigate a realistically complex, changing environment. Innovations in this topic are particularly valuable for designing smarter edge compute in robots or drones, for example.
Conclusion
Based on these experiments (among others discussed in our paper), we can make a few conclusions. Most notably, 1) RL agents performing relatively complex open-ended tasks can learn sophisticated animal-like behaviors that are not apparent from coarse metrics such as reward outcomes, and 2) it is possible to discover this behavior and its neural representation underpinnings using analysis techniques originally developed to study animal behavior and biological brains. Additionally, since some of our findings are surprising and not things that RL agents are known to learn without explicit incentives, it stands to reason that applying such techniques to other tasks might reveal interesting behaviors there as well. For example, here, RL agents were found to forage not just by walking in random patterns, but instead learned sophisticated spatial planning and memory.
Looking ahead, this work offers interesting extensions for future research by both theorists and experimentalists. Theorists can take these analyses further by applying them to other model classes. This could be a particularly exciting development for transformer models, which are widely used throughout machine learning but suffer from limited neural interpretability. However, studying their behavior more deeply could help constrain and improve the neural analysis. For experimentalists, this work offers an opportunity to directly replicate some of our results in animals. This could be especially impactful in insect studies, where our findings on implicit planning in small recurrent neural networks could be tested against prevailing and contradictory theories of insect navigation. If such planning mechanisms exist in the insect brain, they should be detectable using analogous techniques to the ones we used.
Overall, this work represents a vital opportunity to accelerate collaborative neuroscience and machine learning research through a flexible naturalistic virtual laboratory. Flexible for use with diverse datasets and tunable task complexity, ForageWorld is a leap forward in research methods for computational neuroscience, and opens the door for experimentalists and theorists alike to test novel ideas about spatial memory, decision-making, and complex neural/behavioral dynamics without building a computational platform from the ground up. We hope to see this free, widely available platform widely used across different model organisms and research areas, to build a more complete, transparent picture of neural and behavioral dynamics in real-world settings.
To learn more, find the code and paper links below.