
This blog is adapted from
Structure, disorder, and dynamics in task-trained recurrent neural circuits
Structure, Disorder, and Dynamics in Task-Trained Recurrent Neural Circuits
March 04, 2026Building task-performing neural circuit models that remain theoretically tractable is a major open problem in theoretical neuroscience, as is determining where the brain sits between random and learned connectivity. We develop a mean-field theory of task-trained recurrent networks that continuously interpolates between these regimes, and find evidence that macaque motor cortex is best captured by an intermediate level of task-specific recurrent restructuring.
Across the brain, neural responses during behavior are typically messy. Motor cortical neurons fire in complex, multiphasic patterns; hippocampal place fields and cortical head-direction cells have irregular tuning; prefrontal neurons carry mixed signals during cognitive tasks. Are the circuits behind this disorder simply random? They cannot be, since random circuits produce chaotic, high-dimensional activity, not the structured dynamics experiments reveal and that flexible, generalizable behavior requires. The answer must lie somewhere in between, with learned structure coexisting alongside randomness. We develop a theory that makes this “somewhere in between” precise, and find evidence that motor cortex lives there.
An RNN Model that Interpolates between Random and Task-Adapted Dynamics
We consider a recurrent neural network of $N$ neurons with preactivations $x_i(t)$ and firing rates $\phi(x_i(t))$ where $\phi = \tanh$. The neurons are coupled through recurrent weights $J_{ij}$ and receive external inputs $I_a(t)$ via input weights $U_{ia}$. The state $x_i(t)$ obeys the dynamics
$$\tau \frac{dx_i}{dt} = -x_i(t) + \frac{g}{\sqrt{N}} \sum_{j=1}^{N} J_{ij}\,\phi(x_j(t)) + \sum_a U_{ia}\,I_a(t) , $$
where $g$ controls the strength of recurrent interactions [1][2]. The network produces output through a linear readout
$$y_a(t) = \frac{1}{N\gamma} \sum_{i=1}^{N} V_{ia}\,\phi(x_i(t))$$
The parameter $\gamma > 0$ plays a central role. At initialization, the activations and readout weights have generic, unstructured alignment, so the sum $\sum_{i=1}^N V_{ia} \phi(x_i(t))$ grows as $\sqrt N$ and the $\frac{1}{N\gamma}$ prefactor drives the output to zero as $N\to\infty$. To produce finite output, the internal activations must develop structured alignment with the readout weights, requiring the recurrent connectivity to adapt. Larger $\gamma$ demands stronger alignment and thus more restructuring of the internal weights; smaller $\gamma$ allows the prefactor to compensate. In the limit $\gamma \to 0$, the recurrent weights need not change at all, and the network operates as a reservoir (a fixed random circuit with only the readout trained).
Different values of $\gamma$ thus interpolate between two regimes that the machine learning theory community calls lazy and rich [3]. In the lazy regime (small $\gamma$), recurrent weights are purely random. In the rich regime (large $\gamma$), learning substantially reshapes the recurrent connectivity to build task-aligned internal representations, a phenomenon called feature learning. The scaling convention we adopt, known as maximal-update parameterization (or μP) [4][5][6], ensures that the degree of feature learning remains well-defined as $N$ grows. Varying $\gamma$ generates a controlled continuum between the two extremes [6].
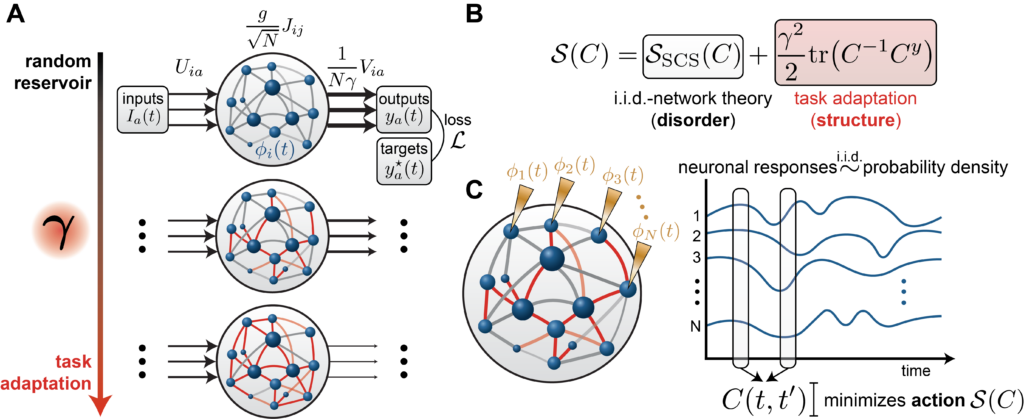
This matters because conventional RNN training yields a single network, one point in a vast space of possible solutions, with no systematic way to explore how internal representations vary. When a trained network happens to resemble neural data, it is hard to know what that resemblance reflects. Is it a consequence of the task? An artifact of the optimization? A byproduct of initialization, architecture, or network size? Our parameter $γ$ provides the missing knob, generating a continuous family of solutions that all solve the same task but differ in how much learned structure they contain.
Mean-Field Theory
What does recurrent restructuring do to the dynamics? In the large-network limit, we answer this exactly using dynamical mean-field theory (DMFT), a technique from statistical physics for characterizing the collective behavior of large, disordered systems. Recent works in machine learning theory have employed this technique to analyze wide neural networks in the feature-learning regime [6][7]. DMFT reduces the full $N$-dimensional dynamics to self-consistent equations for a small number of order parameters, quantities that describe population-level behavior and that are self-averaging (meaning they agree with theory up to fluctuations that shrink as $\frac{1}{\sqrt N}$, so they can be reliably measured from a single large network).
The key order parameter is the temporal correlation function
$$C(t, t’) = \frac{1}{N} \sum_{i=1}^{N} \phi(x_i(t))\,\phi(x_i(t’))$$
This function captures something fundamental about the network, namely, how similar the population’s activity pattern is at two different moments in time. If $C(t, t’)$ is large, the network is doing similar things at times $t$ and $t’$; if it is small, the activity patterns are unrelated. Remarkably, our theory determines this quantity exactly.
Our central result is that $C(t, t’)$ minimizes an action that decomposes into two competing terms:
$$\mathcal{S}(C) = \mathcal{S}_{\mathrm{SCS}}(C) + \frac{\gamma^2}{2}\,\mathrm{tr}(C^{-1} C^y)$$
where $C^y(t, t’)$ is the temporal correlation of the target outputs. The action can be thought of as an energy landscape over possible correlation structures. The network settles into whichever correlation structure sits at the bottom. The first term, inherited from the classical theory of Sompolinsky, Crisanti, and Sommers (SCS) [1] for chaotic random networks, favors disordered, high-dimensional activity. The second term, arising from learning, penalizes misalignment with the target and pulls the network toward low-dimensional, task-relevant temporal structure. The parameter $γ^2$ sets the relative strength of these two forces. At $γ = 0$, only the disorder term survives and the network behaves as a reservoir. As $γ$ grows, the learning term dominates. The trained network reflects the outcome of this tug of war.
The theory also says something important about individual neurons. While $C(t, t’)$ is deterministic in the large-$N$ limit, individual neurons are independent samples from a distribution over response profiles. In the reservoir limit, this distribution is Gaussian, reflecting purely random connectivity. When $γ > 0$, learning introduces a tilting that reweights the distribution, biasing the population toward neurons whose temporal responses align with the task. Neurons remain heterogeneous at all values of $γ$, but the character of that heterogeneity shifts from purely random to task-shaped.
Linear Networks: Amplifying Task-Relevant Frequencies
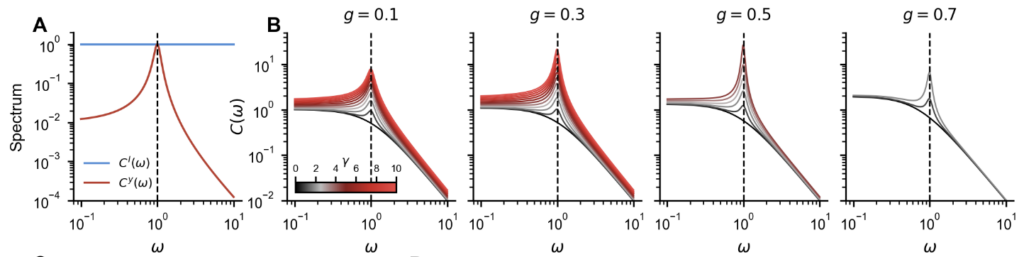
We first built intuition using linear networks ($\phi =$ identity), where closed-form solutions are available. Assuming stationarity, the DMFT equation decouples across frequencies and yields an explicit expression for the power spectrum of the learned network:
$$C(\omega) = \frac{1 + 2\gamma^2 g^2\,\frac{C^y(\omega)}{C^I(\omega)} + \sqrt{1 + 4\gamma^2(1+\omega^2)\,\frac{C^y(\omega)}{C^I(\omega)}}}{2\left(1 + \omega^2 – g^2 – \gamma^2 g^4\,\frac{C^y(\omega)}{C^I(\omega)}\right)}\;C^I(\omega)$$
The ratio $C^y(ω)/C^I(ω)$ measures how much each frequency is over-represented in the target relative to the input, and learning reshapes the network’s transfer function to amplify precisely those frequencies, consistent with observations in prior works on linear RNNs [8]. Figure 2 illustrates this for a network trained to concentrate power around a preferred frequency. As $γ$ increases, the peak around the target frequency grows progressively.
Nonlinear Networks: Suppressing Chaos and Generalizing in Time
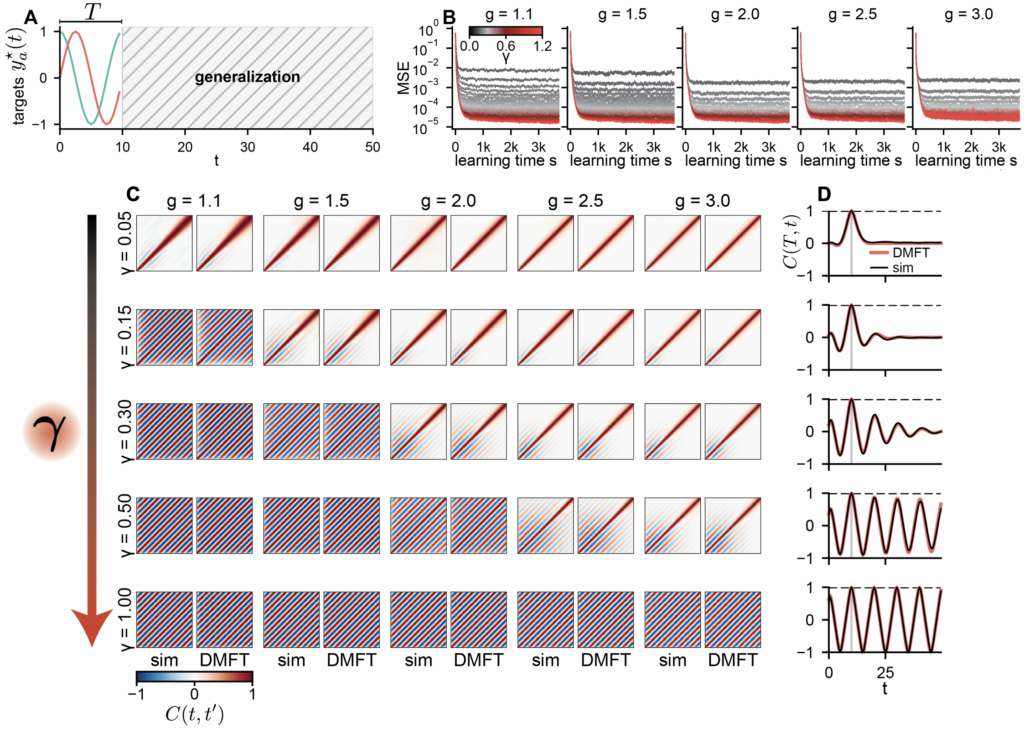
Does feature learning in recurrent networks enable generalization, as it does in feedforward networks [9][10]? We trained a nonlinear ($\phi = \tanh$) network to produce a single period ($T = 10$) of a sinusoidal oscillation with no external input. The target returns to its initial value at $T$, which is compatible with periodicity but does not imply it, since the network sees only one cycle. The question is whether the oscillation persists after the training window ends.
All networks fit the training data well, but what happens afterward depends entirely on $γ$. At small $γ$, the network is dominated by chaos, and the oscillation quickly falls apart. As $γ$ increases, oscillatory structure emerges and grows. Beyond a critical value $γ_\star(g)$, the dynamics undergo a phase transition from chaos to order, settling onto a stable limit cycle that persists indefinitely. The DMFT predicts this phase boundary accurately. Networks that have restructured enough can generalize in time; those that have not, cannot.
A Macaque Reaching Task
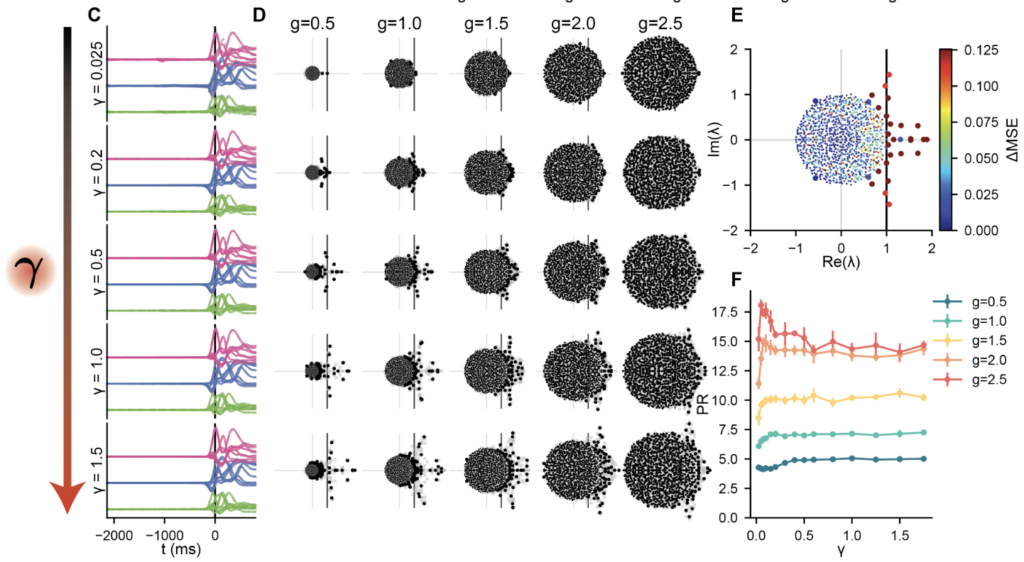
We now turn to a biologically grounded setting. Following Sussillo et al. 2015 [11], we trained RNNs to reproduce the electromyographic (EMG) signals recorded from eight muscles during reaching movements in macaque monkeys, across 27 different reach conditions including straight reaches and curved reaches around obstacles.
Every configuration across the (g, γ) grid produces accurate muscle output. Varying γ yields a family of task-compatible solutions whose internal dynamics differ in a controlled way. The same phenomena from simpler tasks carry over. Outlier eigenvalues emerge from the random bulk, several in complex-conjugate pairs consistent with the quasi-oscillatory dynamics identified in motor cortex by Churchland et al. 2012 [12]. Ablating these outliers degrades performance substantially; ablating bulk eigenvalues has negligible effect. The preactivation distributions evolve from Gaussian at small γ to time-varying non-Gaussian forms at large γ, the tilting mechanism of the DMFT made visible.

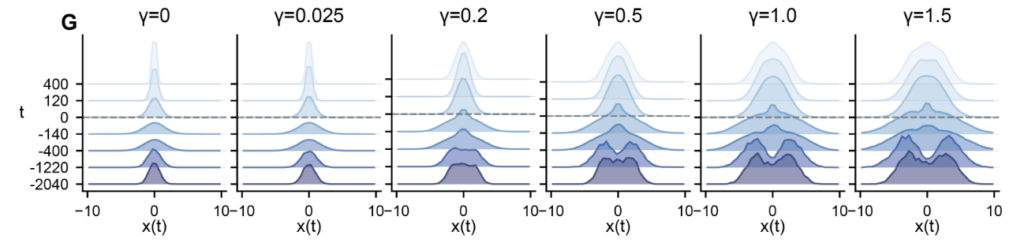
Matching Neural Data Requires Intermediate Levels of Restructuring
Which degree of recurrent restructuring best accounts for real neural data? We compared RNN population activity to simultaneously recorded neural data from primary motor cortex and dorsal premotor cortex (M1/PMd) using centered kernel alignment (CKA), a metric measuring the similarity of two population-level representations.
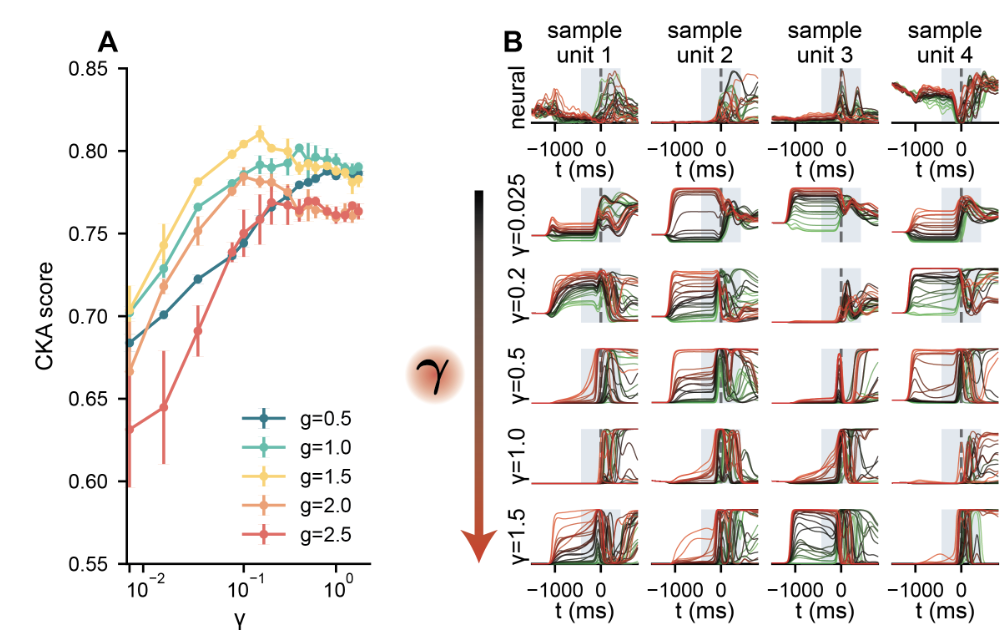
The result (Figure 5A) tells a clear story. Reservoir networks ($γ → 0$) produce accurate muscle outputs but poorly match the structure of neural responses. An intermediate degree of restructuring substantially improves the match. The largest values of $γ$ do not improve it further and can worsen it. The best-matching networks live in a regime where learned structure coexists with random heterogeneity.
At the single-neuron level (Figure 5B), the same picture holds. At small γ, RNN neurons show weak differentiation across reach conditions. As γ increases, neurons develop richer condition-dependent structure, including differentiated ramping and diverse temporal profiles, increasingly resembling the heterogeneous, multiphasic responses of real motor-cortex neurons. At the largest γ values, this selectivity overshoots the neural reference.
Summary and Future Directions
Our framework provides a theoretical account of how structure and disorder interact in task-trained recurrent circuits. The parameter γ generates a continuous family of task-compatible solutions, and the DMFT characterizes how each balances randomness with learned structure. Applied to motor cortex, the picture is one of a circuit that is largely random but contains a modest degree of learned recurrent structure, enough to support the required dynamics.
Several directions follow naturally. Studying how γ controls modular representations in multi-task settings would test whether cognitive tasks demand greater restructuring. The theory also predicts representational drift, with individual neurons’ responses evolving under noisy plasticity while population-level dynamics remain stable [13].
Finally, there is a suggestive possibility about why large neural circuits might favor modest restructuring. Training a readout from a fixed representation requires only local learning rules. Restructuring recurrent connectivity requires propagating error signals backward through time, a computation that is difficult for biological circuits. If the recurrent credit-assignment problem is hard for biology, circuits may settle into solutions that reshape random connectivity as little as needed. In large mammalian circuits, where vast parameter spaces and low-dimensional behavioral tasks create an enormous degeneracy of solutions, selection pressure need only find one.
Acknowledgements
This work was a collaborative effort involving David G. Clark, Blake Bordelon, Jacob A. Zavatone-Veth, and Cengiz Pehlevan. David, Blake, and Jacob contributed equally.
We are indebted to Mark Churchland for kindly sharing data from Sussillo et al. 2015 [11], and for helpful discussions.
A subset of the authors presented preliminary results at the 2024 Computational and Systems Neuroscience Conference [2], including the general dynamical mean-field formulation and the analytical solution for linear RNNs.
This work was supported by the Kempner Institute, the Center of Mathematical Sciences and Applications at Harvard, NSF grant DMS-2134157, NSF CAREER Award IIS-2239780, DARPA grant DIAL-FP-038, the William F. Milton Fund from Harvard University, and the Simons Collaboration on the Physics of Learning and Neural Computation. This work has been made possible in part by a gift from the Chan Zuckerberg Initiative Foundation to establish the Kempner Institute for the Study of Natural and Artificial Intelligence.
This blog is adapted from Structure, disorder, and dynamics in task-trained recurrent neural circuits by David G. Clark, Blake Bordelon, Jacob A. Zavatone-Veth, and Cengiz Pehlevan.
- Sompolinsky, H., Crisanti, A. and Sommers, H.J., 1988. Chaos in random neural networks. Physical review letters, 61(3), p.259.[↩][↩][↩]
- Bordelon, B, Zavatone-Veth, J., and Pehlevan, C., 2024. Mean field theory of representation learning in large RNNs. Computational and Systems Neuroscience (COSYNE) Abstracts.[↩][↩]
- Chizat, L., Oyallon, E. and Bach, F., 2019. On lazy training in differentiable programming. Advances in neural information processing systems, 32.[↩]
- Geiger, M., Spigler, S., Jacot, A. and Wyart, M., 2020. Disentangling feature and lazy training in deep neural networks. Journal of Statistical Mechanics: Theory and Experiment, 2020(11), p.113301.[↩]
- Yang, G. and Hu, E.J., 2021, July. Tensor programs iv: Feature learning in infinite-width neural networks. In International Conference on Machine Learning (pp. 11727-11737). PMLR.[↩]
- Bordelon, B. and Pehlevan, C., 2023. Self-consistent dynamical field theory of kernel evolution in wide neural networks. Journal of Statistical Mechanics: Theory and Experiment, 2023(11), p.114009.[↩][↩][↩]
- Lauditi, C., Bordelon, B. and Pehlevan, C., Adaptive kernel predictors from feature-learning infinite limits of neural networks. In Forty-second International Conference on Machine Learning.[↩]
- Schuessler, F., Mastrogiuseppe, F., Dubreuil, A., Ostojic, S. and Barak, O., 2020. The interplay between randomness and structure during learning in RNNs. Advances in neural information processing systems, 33, pp.13352-13362.[↩]
- Ghorbani, B., Mei, S., Misiakiewicz, T. and Montanari, A., 2020. When do neural networks outperform kernel methods?. Advances in Neural Information Processing Systems, 33, pp.14820-14830.[↩]
- Ba, J., Erdogdu, M.A., Suzuki, T., Wang, Z., Wu, D. and Yang, G., 2022. High-dimensional asymptotics of feature learning: How one gradient step improves the representation. Advances in Neural Information Processing Systems, 35, pp.37932-37946.[↩]
- Sussillo, D., Churchland, M.M., Kaufman, M.T. and Shenoy, K.V., 2015. A neural network that finds a naturalistic solution for the production of muscle activity. Nature neuroscience, 18(7), pp.1025-1033.[↩][↩]
- Churchland, M.M., Cunningham, J.P., Kaufman, M.T., Foster, J.D., Nuyujukian, P., Ryu, S.I. and Shenoy, K.V., 2012. Neural population dynamics during reaching. Nature, 487(7405), pp.51-56.[↩]
- Masset, P., Qin, S. and Zavatone-Veth, J.A., 2022. Drifting neuronal representations: Bug or feature?. Biological cybernetics, 116(3), pp.253-266.[↩]