
This blog is adapted from
Using cognitive models to reveal value trade-offs in language models
Using Cognitive Models to Reveal Value Trade-offs in Language Models
October 07, 2025Note: This blog post is based on work done with Rosie Zhao, Jennifer Hu, Sham Kakade, Markus Wulfmeier, and Tomer Ullman. The work will be presented as a spotlight talk at the Pragmatic Reasoning in Language Models workshop at COLM, and will appear at the workshop on Cognitive Interpretability at NeurIPS.
People’s actions and words are the result of a balance of different goals. The authors use a leading cognitive model of this value trade-off in polite speech to systematically examine how post-training choices like reasoning budget and alignment recipes might be affecting value trade-offs in language models. The authors find that models’ default behavior often prioritizes being informative over being kind, but can easily be prompted to take on, for example, highly sycophantic value patterns.
Social life is full of trade-offs: you might want to go out, while your friend wants to stay in, so you argue or barter or negotiate. But trade-offs of value also happen inside the same head. For example, when your friend asks you how their awful cake tastes, there can be an internal struggle between your values of being honest, being polite, and your care for your friend’s feelings.
People know that other people are going through an internal balancing act between different values when they act and speak. This is part of how we interpret the behavior of others. Ideally, we would want conversational agents (including large language models) to also be sensitive to such value trade-offs in communication. This is important for a variety of social interactions, as the recent example of undesired sycophantic behavior in LLMs shows (‘sycophantic’ meaning the LLMs prioritize pleasing a user over truthfulness OpenAI, 2025).
While we would want to build LLMs that are sensitive to dynamic value trade-offs, current tools for interpreting and evaluating this in LLMs are limited. Here, we expand on the growing toolkit of interpretability methods with “cognitive models” that are designed to explain the structure of human behavior. We apply this tool to a variety of closed and open-source large language models to understand how low-level training decisions shape pluralistic values in LLMs.
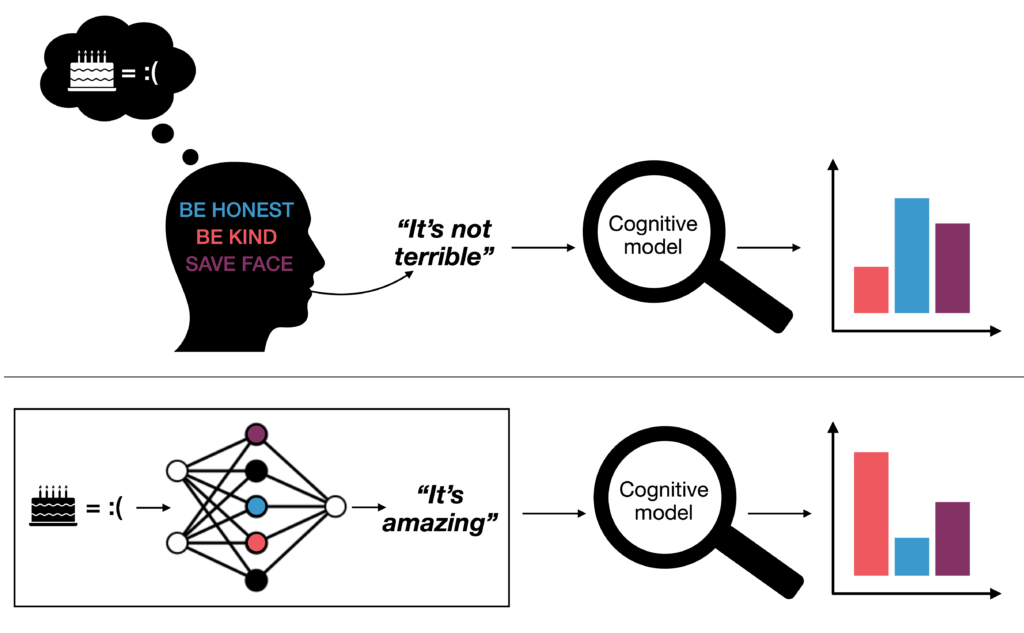
Our results show that the default behavior of reasoning models suggests a preference for information-utility over social-utility. But this preference shifts in significant and predictable ways when models are prompted to act as an assistant that prioritizes making someone feel good over giving informative feedback, and vice versa. Our analysis of the training dynamics of LLMs suggests large shifts in values early on in training, with persistent effects of the choice of base model and pretraining data, compared to feedback dataset or alignment method.
What are cognitive models?
A central line of work in computational cognitive science formalizes human behaviors as probabilistic inference within a generative model of the world and agents. Among these “cognitive models”, Rational Speech Act (RSA) models (Frank & Goodman, 2012; Goodman & Frank, 2016) provide a framework for modeling how speakers and listeners recursively reason about each other to navigate the pragmatic use of language. These models treat communication as a problem of inference, where speakers select utterances with particular goals in mind, and listeners interpret those utterances by reasoning about the speaker’s possible intentions (see Appendix A for a survey of relevant cognitive models).
A cognitive model of polite speech
We consider the computational cognitive framework of polite speech from Yoon et al. (2020), where opposing trade-offs between informational, social, and presentational goals are modeled in the task of giving feedback to someone in socially sensitive situations. We chose this domain because it captures trade-offs between the kinds of opposing utilities that are central to the alignment problem in LLMs: how to convey true and useful information, while providing responses that are agreeable to human users.
The model outputs the utterance choice distribution of a pragmatic speaker S2, given the true state s. The speaker S2 is a second-order agent that takes into account their social partner’s reactions to a possible utterance u. Formally, S2 chooses what to say based on the utility of each utterance in the possible space of alternatives, with softmax optimality α:
$$
P_{S_2}(u|s, \boldsymbol{\omega}) \propto
\exp(\alpha U_\textrm{total}(u;s;\boldsymbol{\omega};\phi))
\qquad \textrm{where}
$$
$$
U_\textrm{total}(u;s;\boldsymbol{\omega};\phi) =
\omega_\textrm{inf}\cdot U_\textrm{inf}(u;s) +
\omega_\textrm{soc}\cdot U_\textrm{soc}(u) +
\omega_\textrm{pre}\cdot U_\textrm{pre}(u;\phi)
$$
The particular parameters of interest are ϕ and ω. The mixture parameter ϕ captures the trade-off between informational and social utilities that the second-order pragmatic speaker S2 wishes to project towards a lower-order pragmatic listener L1. ϕ = 1 indicates high projected informational utility, while ϕ = 0 indicates high projected social utility. The trade-off ratios ω captures how the second-order pragmatic speaker balances informational, social, and presentational goals. Yoon et al. (2020) fit the parameters of this model to interpret the structure underlying complex pragmatic behaviors in humans, and in this work, we do the same to understand LLMs’ behavior (see Sections 2 and 4 for cognitive model and implementation details).
Humans jointly maximize competing utilities
In the original study, human participants were asked to assume the role of the speaker, and to choose an utterance according to one of three goal conditions: trying to give informative feedback, trying to make someone feel good (social), or both. Yoon et al. (2020) find that speakers who have the conflicting goals of being both informative and kind will use more indirect speech when describing a bad state (e.g. they describe a cake that deserves only 1 star as ‘not amazing’). This behavior serves to “save face” (i.e. optimize presentational and social utilities), while still conveying useful information about the true state. It suggests that humans do not eschew one of their goals to increase utility along a single dimension, but rather, choose the utterances that will jointly maximize their competing utilities.
Interpreting value trade-offs in LLMs
We design two model suites for evaluation that examine how post-training features might be affecting LLMs’ ability to capture human-like value trade-offs (see Appendix Table 1 for LLM specifications). In the closed-source setting, we aim to understand the behavioral tendencies of widely-used black-box models, and how their reasoning-optimized variants might be adapting LLM behaviors in everyday contexts where value alignment is critical (cf. Zhou et al., 2025; Huang et al., 2025; Jiang et al., 2025). In the open-source setting, we seek to understand which factors influence model behavior after preference fine-tuning, by systematically evaluating the effects of base model family, preference dataset, and alignment algorithm on the resulting value trade-offs.
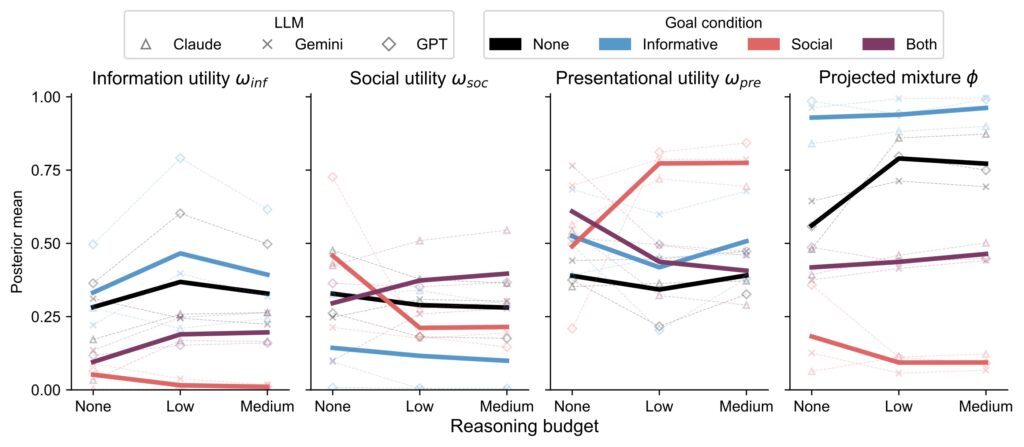
Study 1: Closed-source reasoning models
We find that across model families, reasoning variants display significantly higher projected informational utility than social utility (higher ϕ, black line). Within the Claude and GPT reasoning models we test, we also see a higher weighting on informational utility (ωinf) than their non-reasoning counterparts. We also find that prompting models to assume particular communicative goals shifts their behavior in interpretable ways that are consistent across model families, but more severely than when humans are asked to take on these same goals. This suggests that LLMs can be easily manipulated to eschew certain values in favor of others, instead of maintaining more balanced, human-like trade-offs.
Signatures of sycophancy
We consider the safety concerns of such behavior in light of recent accounts of sycophancy in LLMs. In particular, we hypothesized that under the cognitive model we consider, sycophancy could be described by a combination of: 1) high projected social utility via a low ϕ, 2) high presentational utility ωpre, but 3) low actual information ωinf and social ωsoc utilities (cf. Cheng et al., 2025).
We observe exactly this pattern in the social goal condition (Figure 1, red lines), where LLMs were prompted to act as “an assistant that wants to make someone feel good, rather than give informative feedback.” Compared to their default behavior, in this goal condition, all model families converged to such “sycophantic” utility values, with the sharpest changes occurring at the transition from no reasoning to a low reasoning budget. This shift does not appear as pronounced for the informative (blue) or both (purple) goal-conditions, suggesting that the content of reasoning traces may selectively reinforce certain behaviors.
These findings suggest that even out-of-the-box, behavior-specific cognitive models such as the one we consider for politeness can serve as useful tools for forming and testing hypotheses about other social behaviors.
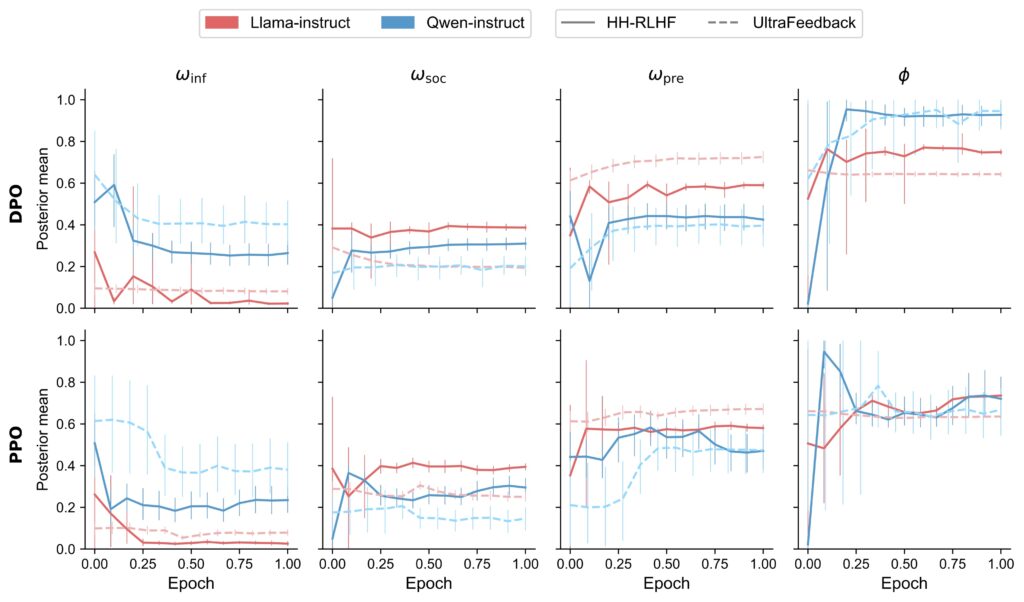
Study 2: Reinforcement learning post-training dynamics
We train all unique configurations of two 7B parameter base models (Qwen2.5-Instruct and Llama-3.1-Instruct), two feedback datasets (UltraFeedback and Anthropic HH-RLHF), and two learning algorithms (DPO and PPO) and evaluate the resulting models’ behavior across evenly spaced checkpoints throughout the preference fine-tuning stage to trace the evolution of value trade-offs during alignment.
Across the inferred parameters of the cognitive model, we observe a number of consistent patterns within combinations of base model and dataset. This aligns with prior work highlighting Qwen’s superior performance in mathematical and reasoning tasks compared to Llama (Gandhi et al., 2025; Zeng et al., 2025).
We also find that alignment to the UltraFeedback dataset leads to both base models converging to a higher ωinf, than when they are aligned to Anthropic’s HH-RLHF dataset. These shifts in parameter values are consistent with the characteristics of each dataset: where HH-RLHF is a human feedback dataset that emphasizes more prosocial qualities like harmlessness and helpfulness, UltraFeedback is a synthetic feedback dataset that contains more diverse instruction-following preferences.
In general, we see that across all four parameters, the largest changes in utility values happen within the first quarter of training, consistent with earlier findings on rapid adaptation during RL post-training in mathematical domains (Zhao et al., 2025).
These findings underscore two more ways that structured probabilistic models of cognitive processes can be used for LLM interpretation: understanding the extent of training needed to achieve desired model values, and guiding recipes for higher-order alignment.
Takeaways
The internal mechanisms of large language models are often opaque to external observers. This is troubling, because understanding the extent to which internal trade-offs of LLMs resemble our own is important to the success of these models as agents, assistants, and judges, and our ability to shape their development towards our ideal visions of these applications.
We used a leading cognitive model of polite speech to systematically evaluate value trade-offs in two encompassing model settings: degrees of reasoning “effort” in frontier black-box models, and RL post-training dynamics of open-source models. Fitting LLMs’ behavior to the parameter values of this cognitive model reveals consistent and predictable shifts in values as a result of training choices. While the default behavior of many closed- and open-source model configurations show a preference for information utility over social utility, these values can be easily – and drastically – manipulated by simple prompt interventions.
Going forward, we are excited to use this framework to expand the set of safety-relevant behaviors we can interpret in LLMs by applying other cognitive models (for instance, loophole behavior; Qian et al., 2024), advance theory-driven mechanistic interpretations of model behavior (“cognitively interpretability”), and guide training recipes that better control trade-offs between values during model development. This framework could also provide a testbed for exploring how human social intelligence may have evolved, by allowing us to probe which trade-offs emerge naturally in large-scale learning systems and which require explicit shaping (c.f. Bonawitz et al., 2020).