
Watermarking in the Sand
November 09, 2023Watermarking is often touted as an important safety consideration for AI generative models. Watermarking has been a key tool for combating AI-enabled fraud and deception. However, precise definitions of what watermarking tamper-resistance actually means are hard to come by, let alone methods that are proven to satisfy it. In a new preprint, we (Hanlin Zhang, Ben Edelman, Danilo Francati, Daniele Venturi, Giuseppe Ateniese, and Boaz Barak) study this question. Unfortunately, we show that strong and robust watermarking is impossible to achieve under natural assumptions. Furthermore, the assumptions we use will only become more likely to hold as AI systems improve in their capabilities and modalities. We also implement a version of our attack on several recently proposed watermarking systems for text generation. Our implemented attack is a “proof of concept” and does not work perfectly or very efficiently. However, because it is just an instantiation of a general principle, the attack is generic and does not depend on the details of the watermarking scheme it is attacking. While the results are negative, not all hope is lost – there are notions of watermarking that can still be satisfied.
What is Watermarking?
Before we can ask the question of whether watermarking is possible, we need to define what watermarking is. Given a generative model for text, code, images, etc., a watermarking scheme consists of a pair of algorithms. The watermarking embedding algorithm modifies the model to “plant” a statistical signal in the output. The watermarking detection algorithm gets an output and detects whether or not it contains a watermark. A watermarking detection algorithm can be either public (everyone can run it) or private (requiring a secret key to run it).

To understand the security of watermarks, we need to consider the point of view of the attacker. Think of a student trying to plagiarize an essay or an agent trying to generate misinformation without the output being detected. The attacker provides a prompt X and gets a watermarked output Y. The attacker’s goal is to leverage Y to find a different output Y’ that has the same quality as Y (in terms of how well it answers the prompt) but is not watermarked.
A strong watermarking scheme is one that can resist all attacks by a computationally bounded attacker, and in particular, one that only has black-box access to the watermarked model and no white-box access to any other model of comparable capabilities. We can contrast this with weak watermarking schemes that restrict not only the capabilities of the attacker but also the set of transformations that it is allowed to make to Y. For example, we might restrict the attacker to change at most a certain fraction of the words in a piece of text or bound the changes it can make to each pixel in an image. Several proposed watermarking schemes satisfy the requirements of weak watermarking for transformations such as these. While weak watermarking schemes can have some uses (e.g., for preventing accidental training on AI-generated data), most adversarial settings require the security of strong watermarking schemes, and this is what we focus on in our work.
Our main result is that under natural assumptions, strong watermarking schemes are impossible to achieve. That is, there is a general attack for any such scheme that can be implemented by an adversary with only black-box access to the watermarked model and white-box access to weaker models. This holds for schemes with both private and public detection algorithms. In the rest of this blog post, we describe our assumptions and why we believe they already hold in many settings and will only become more likely as model capabilities and modalities increase. We then describe our generic attack framework. Finally, we describe an implementation of our attack for several recently proposed watermarking schemes for language models. We demonstrate that the attack can reliably remove watermarks with only a minor degradation in quality.
Our Generic Attack
In our paper, we describe a generic attack on any watermarking scheme. For the attack to work, we need the following two assumptions to hold:
- Verification is easier than generation: Even if an attacker is not able to generate high-quality outputs on its own, they are able to verify the quality of outputs. There are several ways to instantiate this assumption. One is to use weaker open-source models for verifying quality. The other is to simply ask the watermarked language model itself whether the output has high quality.
- The space of high-quality outputs is rich: The second assumption is that, rather than consisting only of a single high-quality output, the set of potential outputs is rich (in a technical sense, described in the paper). While this assumption does not always hold (for example, if a prompt is a math question, there may well be only a single correct answer), it is necessary for watermarking in the first place. After all, in order for a watermarking scheme to have a low false-positive rate, it needs to be the case that the vast majority of possible high-quality outputs wouldn’t be detected as watermarked.
Technically, the two assumptions boil down to assuming that the attacker has access to two “black boxes” or “oracles”: a quality oracle that evaluates the quality of a response Y to a prompt X, and a perturbation oracle that enables the attacker to perform a “random walk” on the space of outputs.
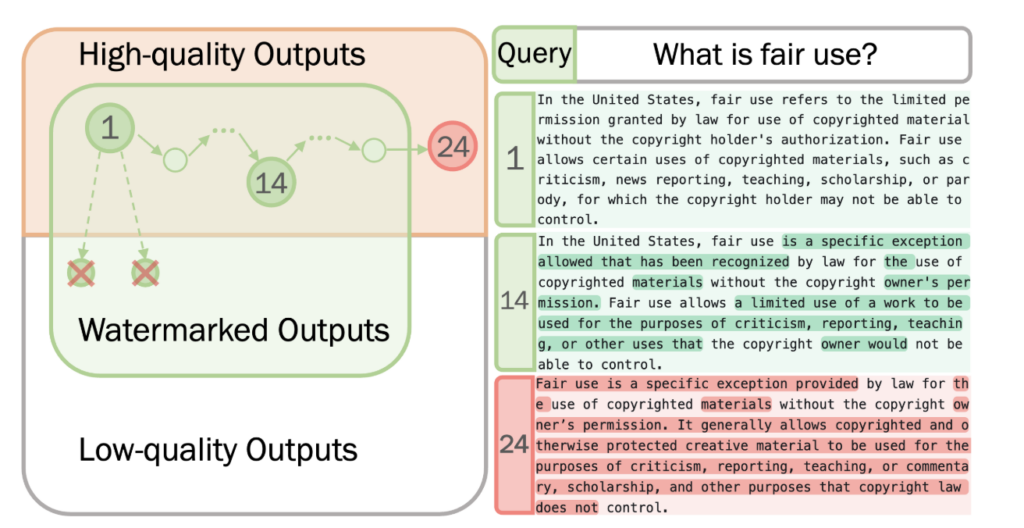
Our main theoretical result is that under these assumptions, there is a generic attack that can break any watermarking scheme. We also show a “proof of concept” by implementing the attack to break several recent watermarking schemes for large language models. While our implementation is not the most efficient way to attack these models, its generality demonstrates the feasibility of the framework. Moreover, perhaps most concerning, our assumptions will only become more likely to hold as AI model capabilities increase.
The idea behind our proof is simple: we use the combination of the quality and perturbation oracle to implement a quality-preserving random walk on the space of all outputs. That is, using “rejection sampling” we can attempt to perturb the output and reject the perturbation if it decreases quality. The “richness” of the space of high-quality outputs corresponds to a mixing property of the random walk. Hence the attacker is guaranteed that the output will be (eventually) random over this rich space. As such, even if the attacker cannot run the (private) detection algorithm, they are guaranteed that the probability that the output is watermarked will eventually converge to the false positive rate.
Implementing the Attack for Text Models
To demonstrate the feasibility of our attack, we implement it for several recently proposed watermarking schemes applied to LlaMA 2: 1) Kirchenbauer, Geiping, Wen, Katz, Miers, and Goldstein (2023) (called “UMD” henceforth), 2) Zhao, Ananth, Li, and Wang (2023) (henceforth “Unigram”), 3) Kuditipudi, Thickstun, Hashimoto, and Liang (2023) (henceforth “EXP”). We consider settings in which the watermark can be reliably inserted (with p-value < 0.05: less than 5% false positive) and show that our attack can reliably remove the watermark.

We measure quality degradation by asking GPT4 to compare the original and the final output. We score the output +1 if GPT4 strongly prefers it to the original, -1 if GPT4 strongly prefers the original, and zero otherwise. We measure the average value across multiple examples (and so +1 means that the judge strongly prefers the adversary’s output to the original 100% of the time, and -1 means that the judge strongly prefers the original output to the adversary’s 100% of the time). The expected value is listed in the table above, demonstrating a mild degradation in quality. We stress that we do not use GPT4 in the course of the attack.
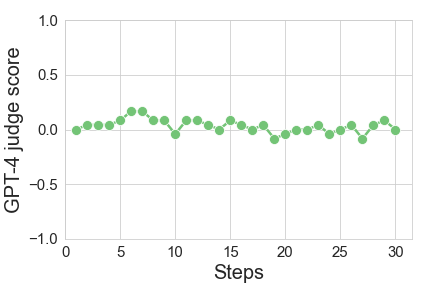
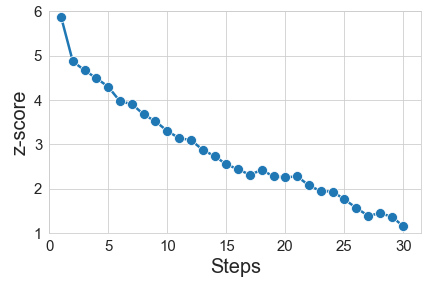
As we perform the random walk, the z-score (# of standard deviations away from the expectation in non-watermarked text) steadily decreases. The quality is generally stable, though with some amount of noise in both directions. We expect that better implementations of the quality oracle, as well as early-stopping heuristics, can ensure more stability and less degradation. (Figure above is for the UMD scheme, averaged over 12 samples.)
We instantiate our perturbation oracle with T5-XL v1.1, which we use to mask sequences of text and propose alternative completions. We use a combination of a reward model (RoBERTa-v3 large fine-tuned on the OpenAssistant dataset) and calls to the GPT 3.5 API to implement our quality oracle. There are many other possible choices for implementations of the perturbation and quality oracles, and future attacks will likely only get better. Our experiments are meant as a general “proof of concept” rather than providing the most efficient way to attack any particular scheme.
Conclusions
Cryptographers often say that “attacks only get better” and this saying is likely to hold for watermarking as well. In fact, there is an asymmetry that favors the attacker since as models become stronger and more flexible, this does not make it easier to embed watermarks, but it does enable new ways to implement the perturbation and quality oracles. For example, new multi-modal APIs could be used to implement quality and perturbation oracles in more flexible ways and for more modalities such as images. In particular, because a quality oracle can be implemented by API calls that have yes/no or single number responses, while a watermarking scheme requires a high-entropy output, an adversary can use an API for such an oracle even if the underlying model is watermarked.
The bottom line is that watermarking schemes will likely not be able to resist attacks from a determined adversary. Moreover, we expect that this balance will only shift in the attacker’s favor as model capabilities increase. Future regulations should be based on realistic assessments of what watermarking schemes are and are not able to achieve.
Note: We believe that investigating the possibilities of watermarking schemes at this stage can help to provide a better understanding of the inherent tradeoffs, and give policymakers realistic expectations of what watermarking can and cannot provide. While our techniques can be used to remove watermarks from existing schemes, they are not the most efficient way to do so, with the benefit being generality rather than efficiency. Moreover, our implementation is for text generation models, while currently widely deployed watermarks are for image generation models. While it is possible to adapt our ideas to attack deployed image generative models, we do not provide a recipe for doing so in this paper. Thus, our work isn’t likely to be used by malicious actors. Rather, we see exposing fundamental weaknesses in the watermarking paradigm as a contribution to the ongoing discussion on how to mitigate the misuse of generative models. We hope our findings will be taken into account by organizations building generative models and policymakers regulating them.