Kempner Research Fellow Andy Keller Wants to Improve How AI Systems Represent a Dynamic World
In a new book, Keller and his collaborators introduce a computational framework that helps AI systems better understand complex and dynamic patterns in data

A new book by T. Anderson Keller (left) and co-authors Yue Song, Max Welling, and Nicu Sebe offers a broad theoretical framework for enabling computational models to recognize persistent patterns in dynamic data that changes over time.
Humans have a powerful ability to recognize patterns in a dynamic, ever-changing world, allowing for problem-solving and other cognitive abilities that are the hallmark of intelligent behavior. Yet despite the importance of pattern recognition in the midst of change, neuroscientists still do not understand how the human brain enables this skill, and AI researchers have had limited success in creating models that emulate it.
Kempner Research Fellow T. Anderson Keller aims to shed light on this mystery. In a recent book, Structured Representation Learning: From Homomorphisms and Disentanglement to Equivariance and Topography, Keller and coauthors Yue Song from CalTech, Max Welling from the University of Amsterdam, and Nicu Sebe from the University of Trento in Italy, offer a broad theoretical framework for enabling computational models to recognize persistent patterns in dynamic data that changes over time.
Keller’s research centers on understanding how brains and AI systems find persistent patterns in data that change over time. Such persistent patterns are known to computational neuroscientists as “invariants,” or aspects of a phenomenon that stay the same when a change or transformation occurs. A common example of this is the human ability to recognize people despite alterations in their appearance. “You change your clothes, or you get a haircut,” says Keller. “There’s still this invariant about you: that is your identity.”
The “identity” or “essence” that enables people to recognize you despite a new haircut is an invariant. To solve problems and pursue goals, humans and AI models need to find invariants in the world: these are the reliable patterns that serve as the foundation for intelligent perception and action.
A major goal of AI and computational neuroscience is to create models that generate invariant representations of different kinds of information. In simple terms, this means representing data in such a way that a computational model is able to recognize important or essential characteristics of an object or data, while disregarding unimportant variables. For instance, AI face recognition software learns invariant representations of people’s faces from large numbers of photographs. With the help of invariant representations, the software can identify people despite transformations in lighting, background, hairstyle, and other factors.
From Invariance to Equivariance
Keller and his collaborators aim to go beyond models that create invariant representations. Their framework centers on a related but more sophisticated concept called “equivariance.”
Equivariance describes a model that is able to recognize invariant information (a person’s identity in the case of face recognition software) but at the same time retain information about the how the data change (that a person has a red shirt on in one photo and a green shirt in another, in the case of the face recognition software). In other words, an equivariant model carries information about the nature of the transformation of data, in addition to the invariant patterns of interest.
Keller uses video as an example of a situation where equivariant representations can be helpful. Say you want a model that tells you if a video contains a dog. For this task, the model only needs an invariant representation of dogs. If you input a video containing a dog exploring a park, any information about the location of the dog will be ignored by a model with an invariant representation.
But what if you don’t just want to know whether there is a dog in the video, but also where it is? “Then suddenly the information about the location of the dog is very important,” says Keller. This means that the model’s output needs to reflect the motion of the dog, and Keller believes that designing models with equivariance in mind is the key to enabling this ability.
The book by Keller and his co-authors dives into the theory and practice of creating models that have “structured representations,” or, in other words, that contain representations that are equivariant with respect to important transformations.
In the book, Keller and his coauthors address the big question of how researchers can build models with the ability to acquire structured representations, given they still don’t understand many of the underlying mechanisms that allow for this capability in the brain or in machines.
Their approach? “Learn it from sequences of data,” explains Keller, who, with his co-authors, presents a variety of methods for getting models to learn structured representations by breaking down sequential data. “The book goes from some biologically inspired ways of doing this through topographic organization and traveling waves, up to more physics inspired ways of doing this through learning potential functions, and following gradient flows along these potential functions.”
The Power of Equivariant Neural Networks
At the Kempner, Keller is continuing to expand the structured representation framework. In a new blog post and preprint, Keller demonstrates the power of the approach, unveiling a new class of neural network models, called Flow Equivariant Recurrent Neural Networks (FERNNs), which can process video data containing moving or “flowing” objects.
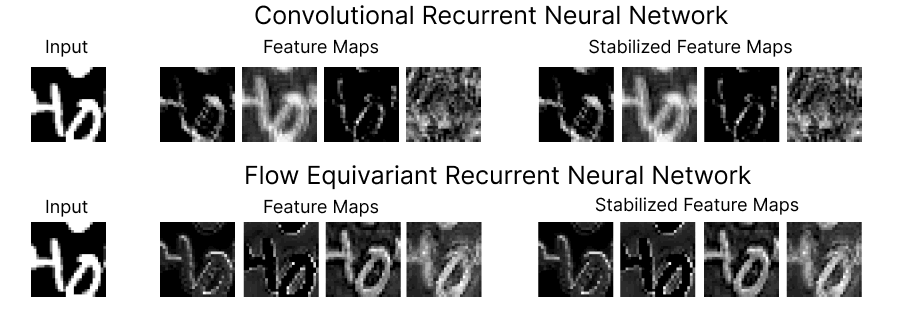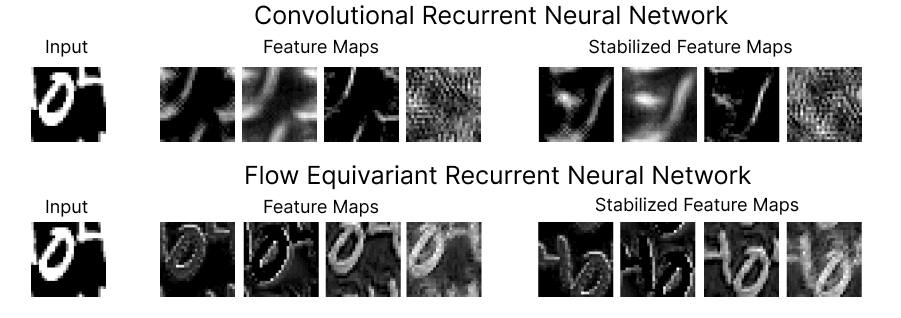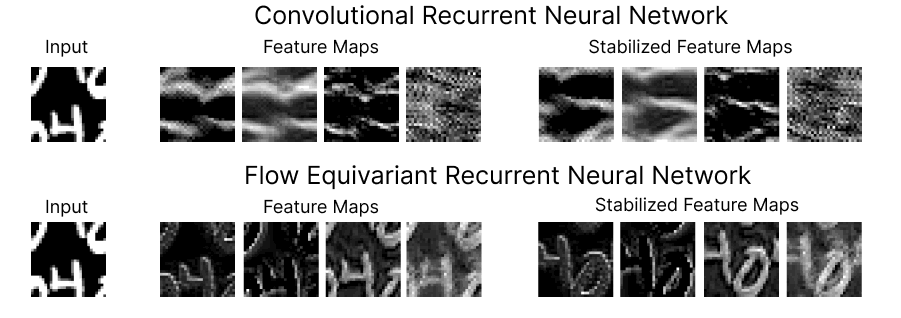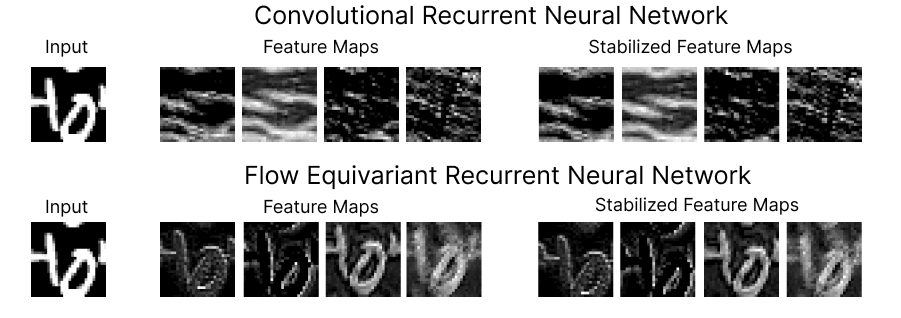
While sequence transformations, like visual motion, dominate the physical world, current AI models struggle to represent them accurately. Keller’s FERNNs are the first ever flow equivariant models, able to account for motion symmetries and allow models to do a much better job generalizing and sequencing information that is dynamic.
Keller sees several practical uses for his equivariance-oriented framework. “The benefits of these methods are data efficiency and generalization,” he says. “These are challenges for robotics, but also for language models and video generation systems.”
Keller is also hoping that this framework sheds light on how the human brain enables equivariant representations. “The most exciting thing for me is trying to see if we can find this type of structure in neural data from real brains,” he says. “Natural neural systems are obviously highly recurrent neural networks, and we know that this is useful for forward prediction and for generating something like a world model.”
About the Kempner
The Kempner Institute seeks to understand the basis of intelligence in natural and artificial systems by recruiting and training future generations of researchers to study intelligence from biological, cognitive, engineering, and computational perspectives. Its bold premise is that the fields of natural and artificial intelligence are intimately interconnected; the next generation of artificial intelligence (AI) will require the same principles that our brains use for fast, flexible natural reasoning, and understanding how our brains compute and reason can be elucidated by theories developed for AI. Join the Kempner mailing list to learn more, and to receive updates and news.
PRESS CONTACT:
Deborah Apsel Lang | (617) 495-7993
kempnercommunications@harvard.edu