New Study Sheds Light on the Kinds of Reasoning Tasks that AI Systems Still Struggle to Do Well
Kempner researchers find that AI systems often fail to perform tasks that require weighing many interacting factors at once

Researchers from the Kempner Institute, including graduate fellows Lukas Fesser (left) and Ada Fang (middle), and associate faculty member Marinka Zitnik (right) have published a new paper that sheds light on the kind of reasoning that AI models struggle to do well.
At a Glance
- A new study by researchers at the Kempner Institute and Harvard Medical School finds that AI systems struggle when given tasks that require reasoning about many interacting factors at once, even for tasks that are relatively simple for humans.
- The researchers introduce a way to measure how difficult a task becomes for AI systems as the number of relationships it involves increases, a quantity which they call “relational complexity.”
- They also present new benchmarks based on tasks from mathematics, chemistry, and biology that allow scientists to evaluate and improve how AI systems handle tasks with high relational complexity.
A doctor deciding how to treat a patient must weigh many factors at once — patient age, medical history, current symptoms, past treatments, as well as possible side effects of treatments — before choosing the safest and most effective treatment.
One major goal of AI research has been to replicate this kind of complex decision-making in AI systems to support human experts. But a new study by Harvard researchers suggests that handling multiple factors at once remains a significant challenge for AI systems.
In a new preprint, researchers at the Kempner Institute for the Study of Natural and Artificial Intelligence and Harvard Medical School (HMS) have introduced a method for quantifying the difficulty of reasoning tasks given to AI systems and offers a way to predict when such systems are likely to fall short. The method involves calculating a quantity known as “relational complexity,” which measures how demanding a task is based on how many entities and relationships must be considered at the same time in order to perform the task accurately. The study also introduces a set of benchmarks, or a set of standardized tests, that AI researchers can use to assess how well their systems handle this type of complexity across a range of mathematical and scientific problems.
“AI is getting better at reasoning, but these models still do not perform perfectly, and they do not fail at random,” explains Marinka Zitnik, Kempner Associate Faculty and Associate Professor of Biomedical Informatics at HMS, and the senior author of the study. “They fail in specific regimens: those that require relational reasoning capabilities.”
The findings show that AI systems — including the most advanced models — perform well when weighing relatively few factors, but their accuracy drops sharply once tasks require reasoning over many interacting factors. This accuracy drop reveals a gap between what today’s AI can do and the kind of complex reasoning required for real-world applications in medicine, science and other domains. “The core message of this study on relational reasoning is that current AI systems struggle, not necessarily because tasks are large, but because they require reasoning about many interacting pieces simultaneously,” says Zitnik.
When More Pieces Make Reasoning Tasks Harder
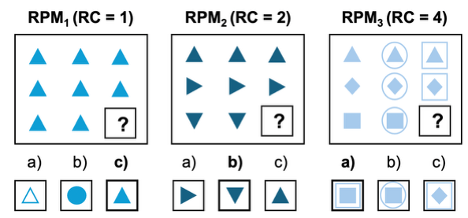
Image credit: Lukas Fesser
To assess how well AI systems perform on tasks with different levels of relational complexity, the researchers created a series of benchmarks in mathematics, chemistry, and biology. One example from the set of math benchmarks is based on Raven’s Progressive Matrices — a type of puzzle which is widely used for human cognitive assessment.
As the researchers increased the relational complexity of the matrix puzzles, the performance of AI systems dropped sharply.
“If you make [the tasks] even marginally harder, the model starts to fail, and it fails in a very predictable way,” says Lukas Fesser, Kempner Graduate Fellow and a co–first author of the study, along with Kempner Graduate Fellow Ada Fang, and Yasha Ektefaie, an Eric and Wendy Schmidt Fellow at the Broad Institute of MIT and Harvard and a former Ph.D. student in the Zitnik Lab.
These failures were especially surprising because the tasks Fesser and his collaborators used were not the large and memory-intensive kinds of tasks that were previously known to strain AI systems.
“Normally, to find a failure mode you need these huge inputs,” says Fesser. Instead, the researchers found that as relational complexity increased, performance dropped well before the models’ memory limits were reached.
Towards Models That Can Handle Relational Complexity
The researchers now plan to use relational complexity in the development of future AI systems. One direction they are exploring involves training models on tasks that involve many interacting factors by using reinforcement learning — a method in which AI systems learn and improve through feedback.
By introducing a way to measure relational complexity — and providing benchmarks to test how well AI systems handle it — the team hopes to add a new dimension to how scientists quantify progress in the capabilities of AI systems. While progress is often characterized in terms of how large the AI systems are, how much data they are trained on, and how much computing power they require, Zitnik says that relational complexity is another important dimension to consider.
“AI performance is often studied as a function of data and compute to understand scaling laws,” says Zitnik. “Our study shows that it can also be studied as a function of relational complexity, offering another way to understand the capabilities of AI systems.”
“It’s not solely about [whether] models are smart. It is [about what] kind of reasoning they fundamentally fail at, and what kind of reasoning they perform well on.”
***
To learn more about the work, check out the project’s homepage, GitHub repository, and Hugging Face repository.